———
We should all take a moment to reflect that going to school should be a safe, happy, and memorable part of everybody’s life. That was taken away this week from 19 children because common-sense laws, licenses, and checks do not apply to deadly weapons in this country. They apply to get a car license, to require car insurance when purchasing a vehicle, or to purchase Sudafed for a stuffy nose. I reside just 25 minutes from Sandy Hook Elementary school. My church has a memorial for that tragedy. As a parent, I could not comprehend what the grief of loss could be. My prayers to everybody affected in Uvalde, and to all other school districts this year, last year, and all years before that.
———
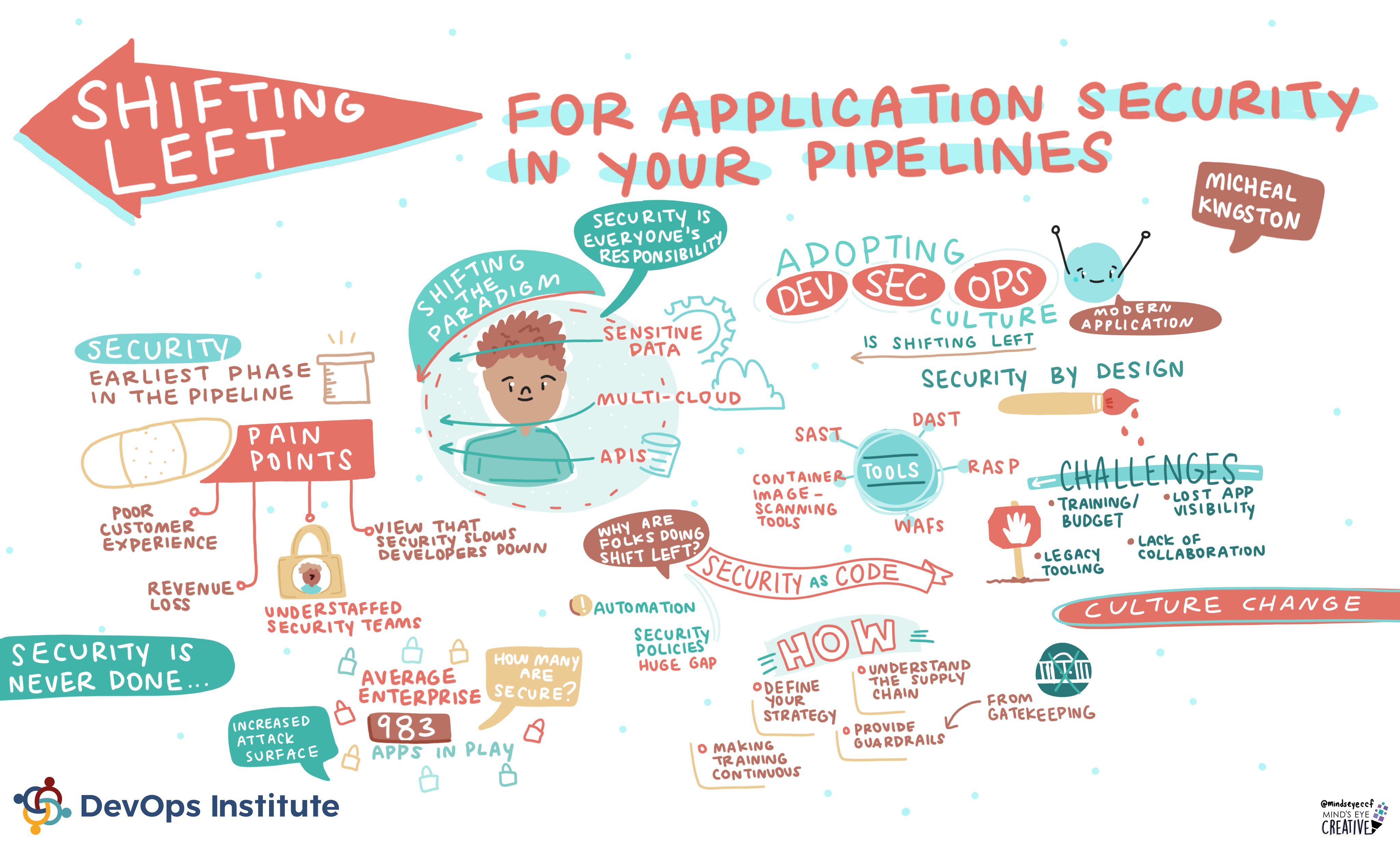
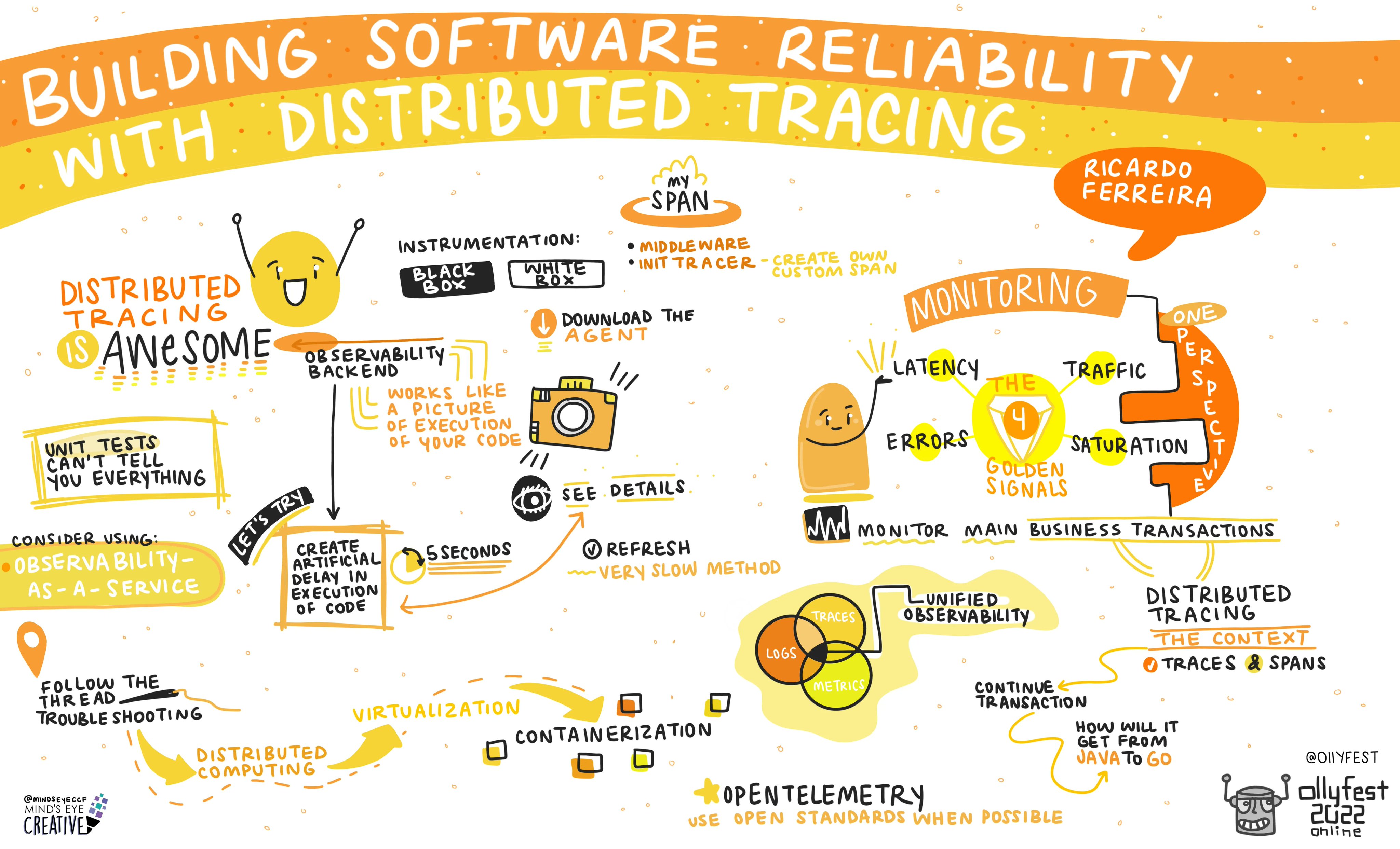
In recent months I have focussed on improving my data visualization technology skills, and working on my data storytelling skills. 3 Tips You Need to Be Successful in Data Visualization sums this up well. “Data visualization is not just a skill, it’s a lifestyle. Keep learning and find new ways to get better”. If you are interested, my favorite physical book to date on the subject area is Effective Data Storytelling by Brent Dykes. Great detail, as well as great quotes. This week Brent has published 100 Essential Data Storytelling Quotes from his book which is a timely affirmation.
How well we communicate is determined not by how well we say things but how well we are understood” — Andrew Grove
More reading and discussion on what is Web 3.0? What does it mean for our field? What does it mean for my future skills? The hard truths about Web3: What no one else is talking about was something I read this week after it was recommended by a good friend. The takeaway is in the closing thoughts “Instead, educate yourself on the long-term sustainable use cases of blockchain technology.”. My friends’ takeaway about Blockchain is “It’s a tool, not a solution.” I would tend to agree.
I launched a new project last weekend and I’ve selected for a second time to go with Hugo for a static site generator. If you want a drag and drop template well it’s good, but there is definitely a learning curve if you want to make just minor tweaks. My theme for example said it included Bootstrap, but I wanted to accent a post with a TIP box (in Bootstrap they are called Alerts). Do you think it was trivial to work out why Bootstrap alerts didn’t work in my Hugo template? I spent over an hour because of the complexity of a low-code, no-code solution, whereas if I’d built a site with straight HTML/CSS/JS/Bootstrap it would have just worked. Maybe I’m old school, but clean code and not three levels of abstraction is IMO more maintainable. Does it take longer to be productive? At the start of a new project perhaps, but if you don’t have very technically capable resources that are at your avail, the selection of an internal tool for an essential part of your business may be a poor choice.
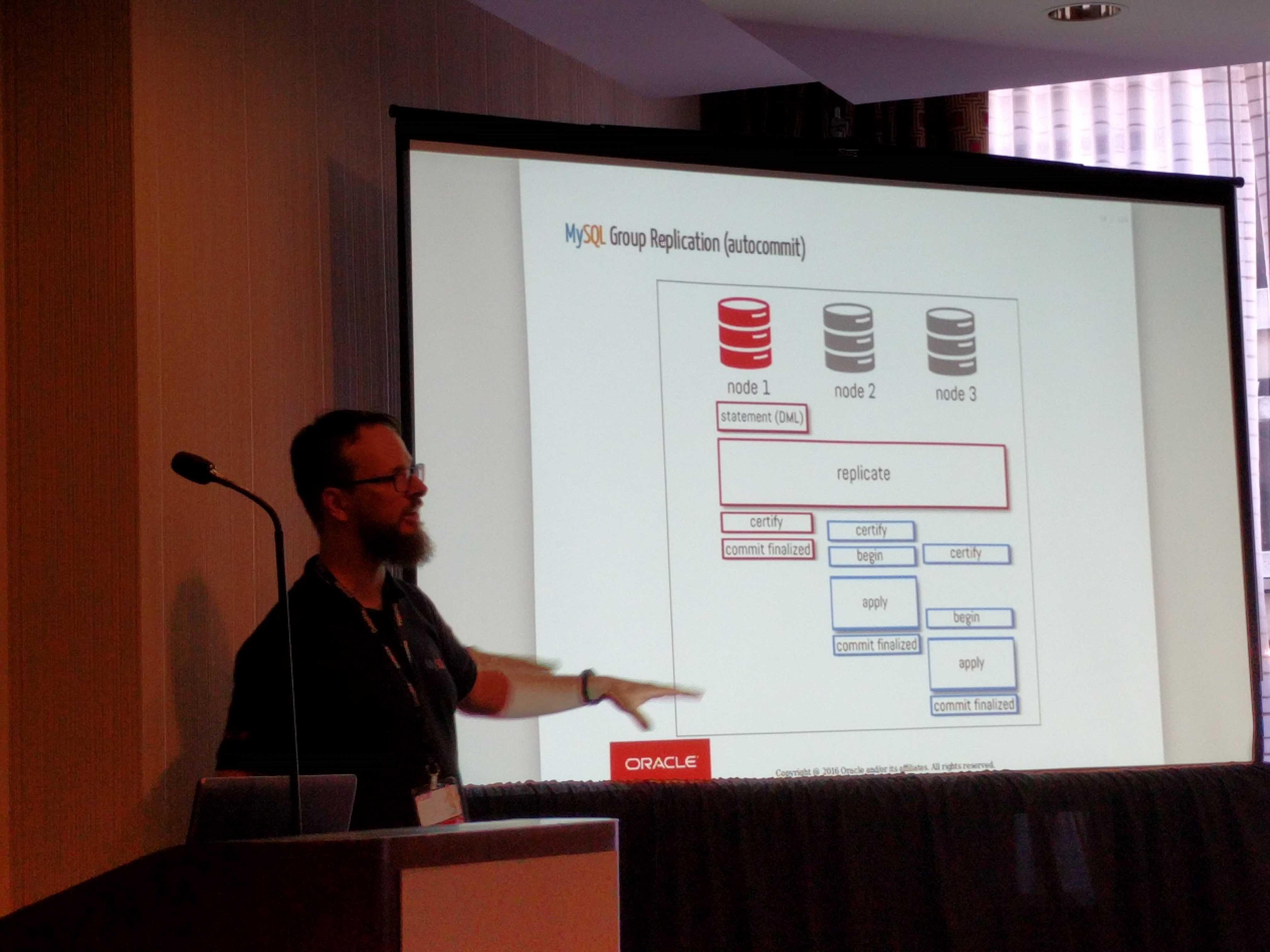
As an example. Last year my employer suffered a long outage due to the rough AWS Cloud Dec 2021 with three separate incidents. In one occurrence, the loss of power to a data center that knocked out approximately 7% of one AZ would not be an issue for any organization’s business that runs in a highly available multi-AZ model right? Wrong. The use of a Docker Container Registry product, that was configured has HA went down, along with multiple nodes. Those nodes could not be relaunched because the registry was down. The images could not be rebuilt because they relied on additional images. The entire site was degraded because of one component that was configured in a HA capability, but it was configured incorrectly. To further complicate the matter, the entire stack, from the IAAS to underlying technologies was not part of the stack the DevOps team used, and without clearly documented installation, testing, and chaos experiments. To further complicate the issue, this required obtaining commercial support for the product being used right then, opening a ticket, and getting a support person of said commercial company to help address the issue. The moral here is. If your business relies on it’s availability and you do not have the technical skills and capabilities and redundancies of your staff to ensure its availability, then are you really thinking hard about being prepared, or are you chasing the next sale, the next feature, the next new wave of technology?
Want to get your links to render nicely in the varying products you use? Twitter Card Validator can be a bit of a hit/miss effect. I have found that if I cut/paste a link in chat programs including Slack, Google Chat, and Signal which all provide a different experience but seem to be more responsive. I guess I will keep working on it. (Damm you Hugo!)
On a more personal note and a sore pain point is 401k retirement plans and planning for retirement in the U.S.A. Have you been burned by the 3-year vesting rule of your employer’s matching contributions that you didn’t know about when you looked at the initial offer package? I have. It seems it’s a wide industry problem that affects all levels of employees. Opinion: This giant pension scandal is hiding in plain sight. You are expected to financially plan for retirement only to find that limits, types of plans, and employer decisions put roadblocks in your way.
This week in images.
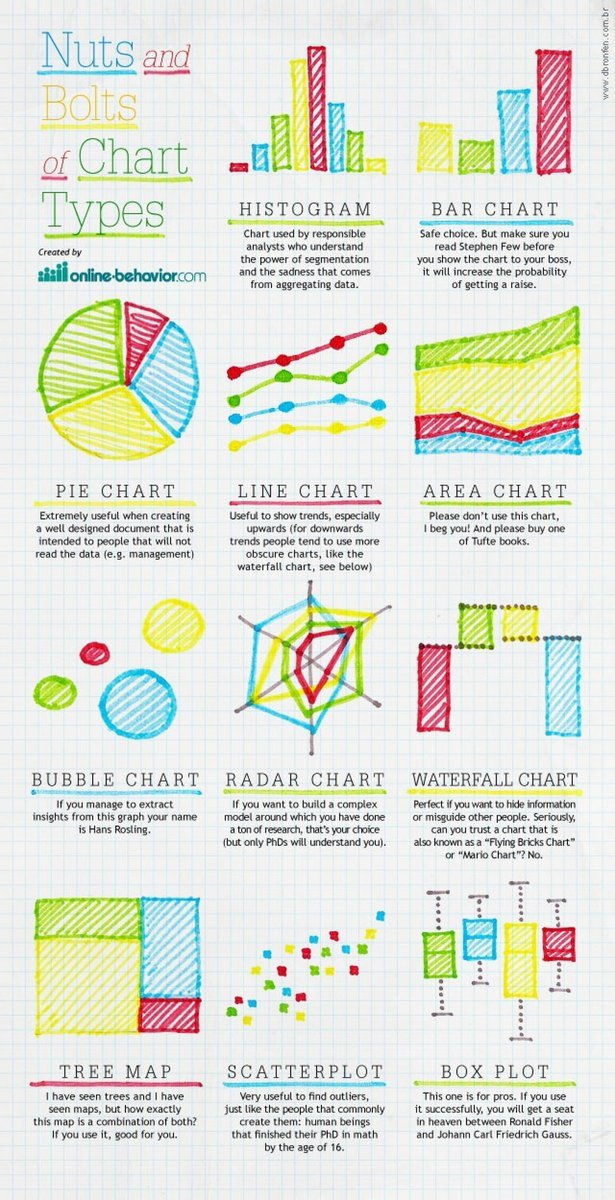
- Nuts and Bolts of Chart Types
- Thanks @matplotlib for answering my question about how do I create animated bar charts with the skills I know. Well the answer is https://github.com/dexplo/bar_chart_race
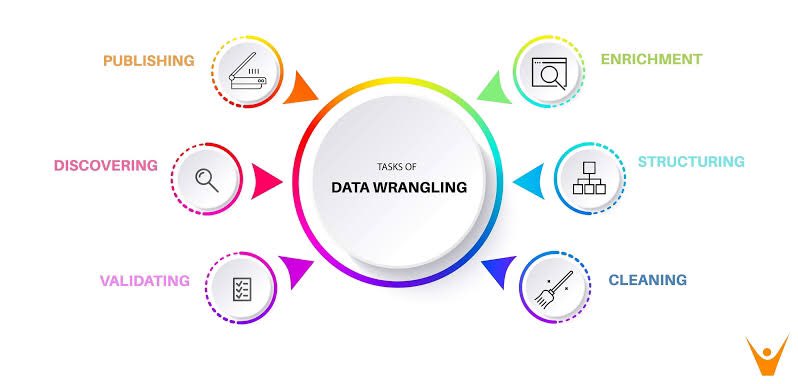
- Steps of Data Wrangling
- Cute
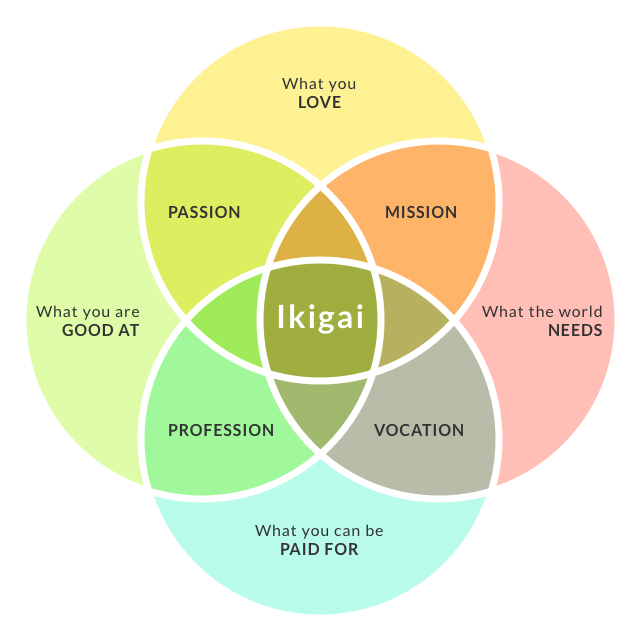
- Ikigai Look it up!