Blog
![Digital Tech Trek Digest [#Issue 2024.08]](https://ronaldbradford.com/images/blog/2024-digital-tech-trek-digest.png)
Digital Tech Trek Digest [#Issue 2024.08]
The One Billion Row Challenge Shows That Java Can Process a One Billion Rows File in Two Seconds Well, it’s way under 2 seconds for the 1brc . The published results are in, and if you’re good, you can read 1 billion data points of weather data and analyze it.
Read moreDigital Tech Trek Digest [#Issue 2024.07]
Everything you need to know about seed funding for startups A recent call with a startup founder funded by TinySeed led me to learn about MicroConf and Rob Walling. (Thanks Tony for the info).
Read moreDigital Tech Trek Digest [#Issue 2024.06]
MySQL Belgian Days 2024 and FOSDEM 2024 In this past week, I’ve been able not just to read or watch digital content online but to meet people in person. In Brussels, first at the MySQL Belgian Days 2024 event, followed by FOSDEM 2024 .
Read moreDigital Tech Trek Digest [#Issue 2024.05]
Because the world needs better dashboards While my professional interests in Building Better Data Insights Faster rely on using visuals and narratives to show data-driven results, “Starting from first principles” is the question you have to ask.
Read moreDigital Tech Trek Digest [#Issue 2024.04]
NoOps and Serverless solutions I was reminded of an upcoming expiry of a test website that I have on PythonAnywhere . This site enables you to host, run, and code Python in the cloud without any infrastructure and starts with a free account and then a $5 account.
Read moreDigital Tech Trek Digest [#Issue 2024.03]
Lessons from going freemium: a decision that broke our business As an entrepreneur always considering how to produce a sustaining passive revenue, what licensing model to use, and how to acquire and retain customers, the allure of a freemium model is ever present in so many offerings.
Read moreDigital Tech Trek Digest [#Issue 2024.02]
Indie Newsletter Tool Generates $15,000 a Month There are so many different email newsletter sites you could wonder if there is market saturation. MailChimp , Mailgun , ConvertKit , Sendgrid (now part of Twilio it seems), Moosend and Mailersend come to mind.
Read moreDigital Tech Trek Digest [#Issue 2024.01]
The Tiny Stack (Astro, SQLite, Litestream) I spent many years in the LAMP stack , and there are often many more acronyms of technology stacks in our evolving programming ecosystem. New today is “The Tiny Stack”, consisting of Astro , a modern meta-framework for javascript (not my words), and Lightstream Continuously stream SQLite changes.
Read more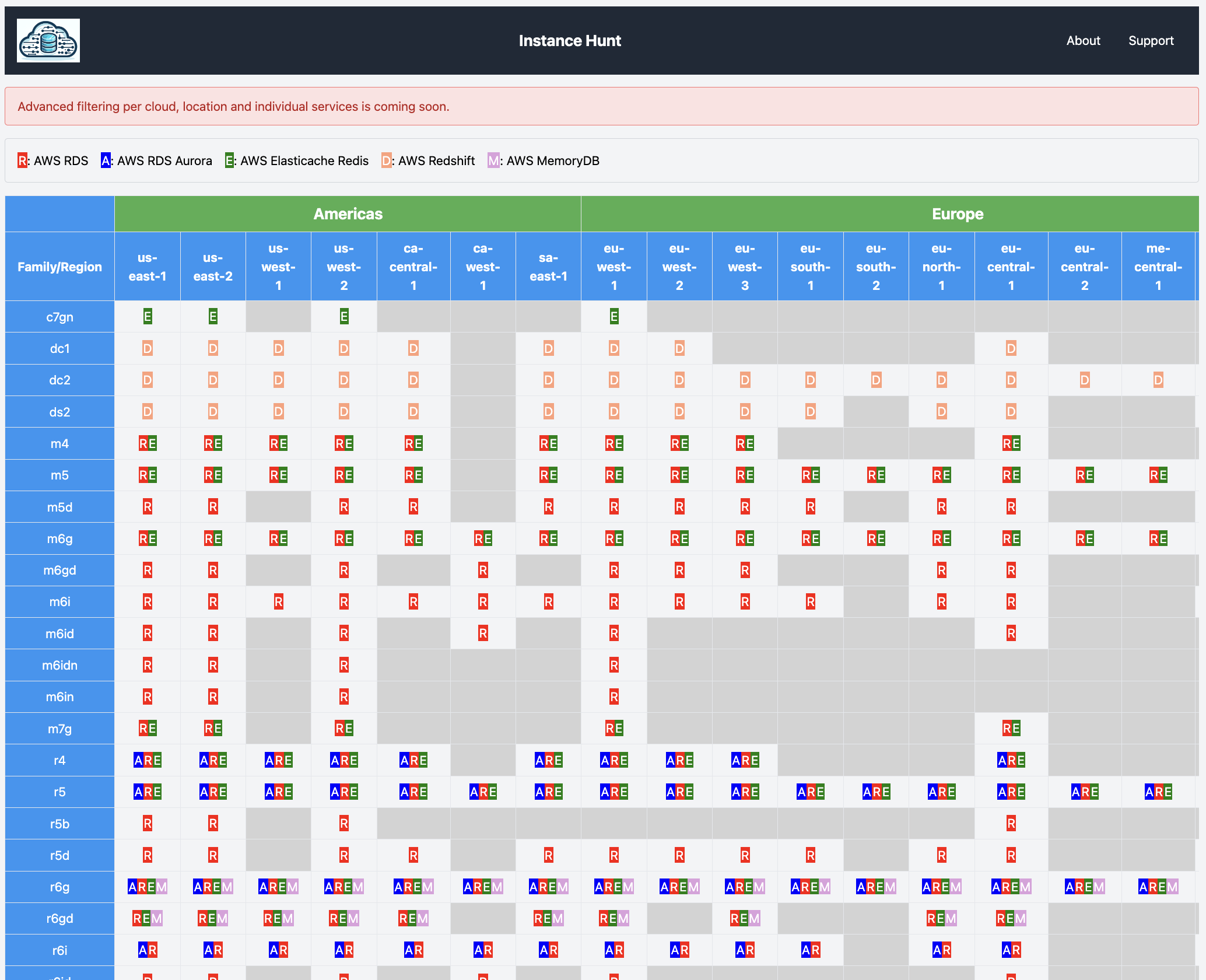
Announcing InstanceHunt
InstanceHunt identifies the instance (families/types/classes) available for a cloud service across all the regions of that cloud. The initial version is a working example of several AWS database services. Future releases will enable advanced filtering and will cover other service categories (e.
Read moreMastering MySQL 5.7 EOL migrations
In a recent podcast on Mastering EOL Migrations: Lessons learned from MySQL 5.7 to 8.0 I discuss with my colleague Adam North not only the technical issues that become a major migration but also key business and management requirements with having a well-articulated strategy that covers:
Read moreData Masking 101
I continue to dig up and share this simple approach for production data masking via SQL to create testing data sets. Time to codify it into a post. Rather than generating a set of names and data from tools such as Mockaroo , it is more practical to use actual data for a variety of testing reasons.
Read moreA reliable and dependable application requires observability
Observability (o11y) is a critical pre-requisite component in software architecture when advocating for and preparing organizations for making informed decisions on the success of their application. Open Telemetry from the Cloud Native Computing Foundation is the goto standard regardless of your choices of monitoring tools.
Read moreAWS RDS Aurora wish list
I’ve had this list on a post-it note on my monitor for all of 2022. I figured it was time to write it down, and reuse the space. In summary, AWS suffers from the same problem that almost every other product does.
Read moreOur Data Security Moonshot Starts With Prevention
The recent re-announcement of the Cancer Moonshot highlighted a common enemy to many endeavors to improve our society as a whole, and that is using common sense and already known methods.
Read more