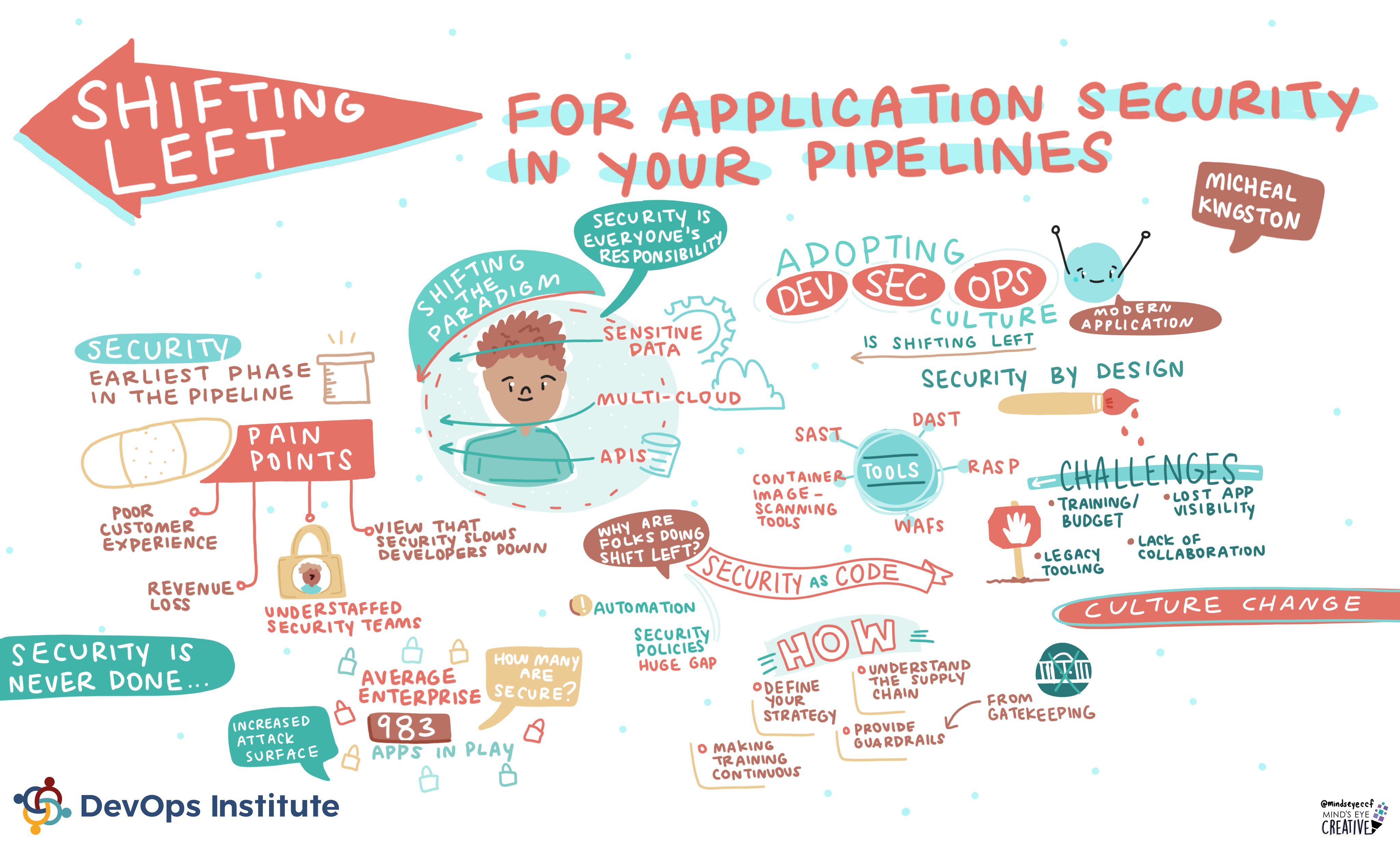
While this is a catchy title, if you use Software as a Service (SaaS), or an online cloud provider, do you actually own and have total control of your business data and its infrastructure? For all the free and paid services your business uses, what happens if one day, a portion of that were no longer available?
When you have data in a CRM, an analytics platform, a marketing platform, a payments platform, if one of those service providers locks you out of your data, you have lost control and access to a part of your business. Can you still operate unaffected? What is the actual impact? What is your contingency? You could be lucky and the impact is temporary, such as a day or a week, but it could also be longer or even indefinite.
Let me give you a simple but concrete example. Fellow woodworker Eric of Spencley Design posted recently on YouTube “I just lost half of my business”. If you listen to just 2 1/2 minutes from 12:00 to 14:30 of his youtube video explanation you will understand that this business relies on several online SaaS services. Many are free, but for an unexplained reason, whether bad code, bad ML/AI, or several other plausible reasons, one of his income streams was shut down without notice. This was not by his doing, or any of his actions but for unrelated reasons. Online attempts to appeal this situation caused a permanent suspension. Talking to a human to understand what happened, why it happened, and how this can be resolved, was also unanswered because there is no ability to physically speak to a human.
This problem is not limited to online services. A great example of just a decade ago is your business credit card stops working, transactions are declined. If you were lucky you could physically call your bank manager, or go to your bank manager to get to the bottom of the situation. You knew your bank account contained sufficient funds as you maintained on-premise accounting practices and you could provide evidence of such facts. If you run a small business today, do you think you can talk to a human that would have the ability to correct this problem, or would you have to talk to 5 humans, multiple automated (and annoying) systems, costing countless hours of time and frustration?
If you rely on Acme George Inc workspaces product for your small business email and shared documents, what if that becomes blocked? How do you communicate with your customers? What if you use Acme Archie Inc for your customer support ticketing system, and for a week it is unavailable to use? Not only can your customers not report issues, but you have no access to see what issues were already outstanding and work on them independently.
At times there are widespread outages of online presences that have a wide effect across industries from hours to weeks. Cloudflare Jun 21, 2022, Fastly June 8, 2021, Amazon Web Services Dec 7, 2021, and then Dec 15 and Dec 22. A blog post called it the AWS’s December Outagepalooza. The Atlassian April 2022 outage for paying customers lasted upto 2 weeks. Even a free social media company and its related entities incurred widespread impact Facebook Oct 4 ,2021 that affected many gig economy businesses. These outages can have far ranging effects. Actual examples include you cannot pay your employees, your staff at a hospital cannot authenticate to access patient records, transportation and logistics of your shipping business is halted.
I am referring here to loss of access to your data in a SaaS environment, and loss of cloud infrastructure that supported your SaaS services or even your internally developed and maintained systems running on cloud infrastructure. If you are not convinced of the larger ramifications of an extreme loss of infrastructure services what was the impact to Parler in 2021.
My point here is you cannot simply stop using these services, or your cloud provider(s) infrastructure. You need to be prepared. In a traditional system, you backup your data for some degree of disaster, and you support the capability to recover both infrastructure and data from this, and if you a smart you actually test this. Sidebar a colleague recently shared that even with massive investment in infrastructure and global redundancy, a scheduled test for this large bank took down services for 12 hours.
Large SaaS organizations could offer services that offer multi-region or multi-cloud capabilities, but they are also at the mercy of the SaaS providers they use. Do you know all the interdependencies? Look no further than the wipe out of Okta’s stock (down 30%) in one day. CEO of Okta Todd McKinnon cited several factors including a security impact by text message provider Twilio. Read more about that at Twilio Employeee, Customer Accounts Breached Through Texts. And yes, the headline here has an incorrect spelling. I tried to add a comment to offer feedback, but the MarketWatch paywall of 4 articles would not let me create an account to login to leave a comment!
The solution is not to host all of your own infrastructure either. Facebook’s very long outage was self-inflicted and they controlled all of their own infrastructure. It not only had an impact on their websites, their internal staff were unable to use security badges to access critical infrastructure to correct the problem because they were physically locked out of buildings holding the infrastructure.
Returning to the small business owner who uses a marketing platform, an analytics platform, a CRM, a payment platform or even a social media platform. Do you keep current copies of your data in these systems so that if there were a loss, you knew who to communicate with? In the first cited case, did Eric have a list of all of his subscribers, a copy of all his online content, and all comments made by subscribers. Was there a means to communicate with them via other means, or was access to sufficient PII not even possible for what was his original content?
In future posts I will share some of my techniques for ensuring you have a data acquisition strategy.