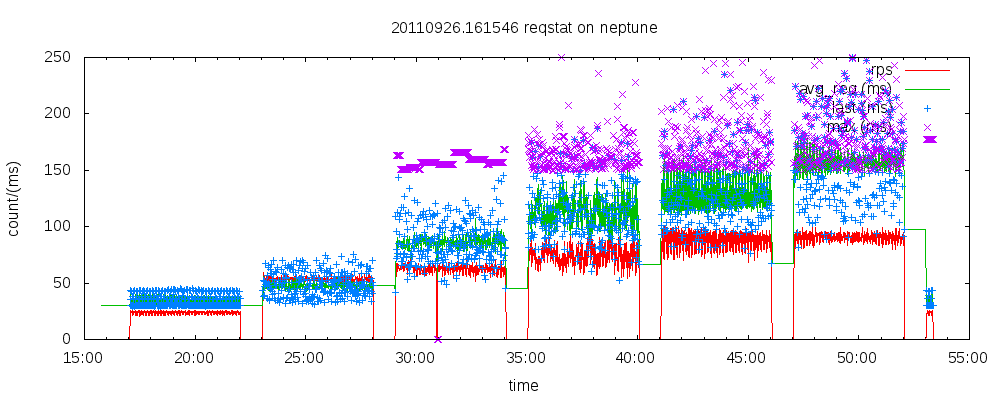
When using the replication slave stream, or mysql command line client and mysqlbinlog output from a binary/relay log, all statements are executed in a single thread as quickly as possible.
I am seeking a tool to simulate the replay of the binary/relay log for a benchmark at a pace that is more representative to original statements. For a simple example, if the Binary Log has 3 transactions in the first second, 2 transactions in the second second, and 5 transactions in the third second, I am wanting to simulate the replay to take roughly 3 seconds, not as fast as possible (which would be sub-second). The tool should try to wait the remainder of a second before processing SQL statements in the incoming stream.
Does anybody know of a tool that currently provides this type of functionality? Any input appreciated before I create my own.



 Announced on Sunday at
Announced on Sunday at 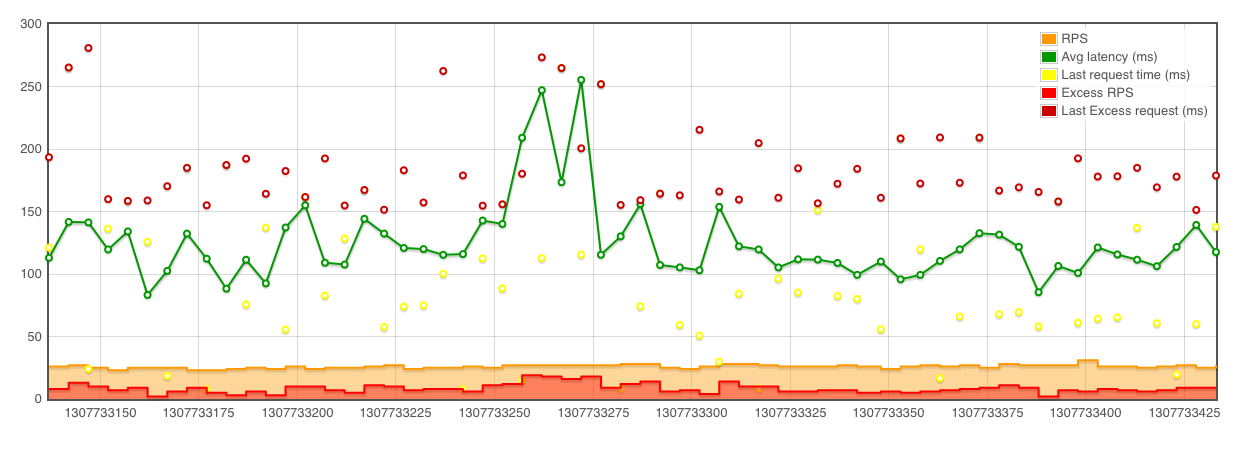
 At the closing keynote of the recent
At the closing keynote of the recent 
 I will be joining a stellar class of speakers at the
I will be joining a stellar class of speakers at the