A large part of my work week was spent u-hauling across 1/3 of the country. This was a very mentally intense time, indeed 8-10 hrs per day of concentration working with dangerous equipment and sometimes in unpredictable situations with little break was harder than sitting at a desk. I had a lot of time to look at all those trucks on the highway and compose some thoughts about improving our planet. Yes, I did pay $5 per gallon for fuel, and at one stop $150 didn’t even fill the tank.
Easily 50% of all vehicles on the highway were semi-trailer trucks, a cab hauling one or two trailers (henceforth just trucks). If 100 trucks are moving from Point A to Point B, and let’s say it’s 8hr to 16hrs in travel distance, it is highly possible for longer trips you are also away from family. That’s 100 people that are always on, focused on the sole task of driving, you cannot step away for a quick break like in other roles. Electric vehicles will reduce emissions, but that’s not solving the problem. Driverless vehicles will help but that is also decades away from practical use. While 90% of vehicles will remain operated manually for many decades if not always, I see this as an impractical short-term solution.
I had to feel that rail is the obvious alternative here. You can with fewer individuals haul 100 containers, which reduces the human impact. The track is fixed, providing you have the correct support for trains in the opposite directions, so no dealing with the varying speeds of vehicles and crazy drivers. That reduces the mental complexity, and it also reduces the volume of larger vehicles with passenger vehicles. But rail has significant limitations in the change in elevation and direction unlike a road. Any tangible improvement to reduce traffic on highways would work best in areas of flat country. Is this geographical limitation alone a sufficient deterrent.
However, a train goes from point A1 to point B1. It still requires transportation of the container from individual companies’ locations A to A1, and B1 to B. These are much smaller distances and require those 100 drivers, however, they spend less time on the road, less stress on long-hauling, less time away from family. You also cannot just drive the trailer onto a rail car, so there is the complexity, and bottleneck of getting containers onto and off of trains. So is there a way to solve the actual problem of too many vehicles with so much human requirement that also requires concentration and attention, and a volume that is every increasing. The reason this would never work is capitalism. We live in a world where every company wants their own trucks, their own product traveling on their own schedule. Until we stop thinking like 1000s of individual companies and 100s of individual countries to focus on 10s of critical problems facing the planet, I feel the root cause is never actually being tackled. Ironic that in software engineering, the same issue of not tackling the actual root cause in larger strategic ways also occurs.
Changing topics. Let me start with a technical analogy of the following real-life experience.
You have terrible technical debt. They may be known reasons why this occurred in the past, but those reasons and those people are long gone. Yet all subsequent workers suffer from this accumulated technical debt and the impact on product quality and time efficiency is never actually measured or calculated but it should because the impact would be staggering. Vain attempts are made to make some improvements but the amount of technical debt grows, as the number of people writing code grows, the number of varying tools and their apparent effectiveness grows making it all easier to access faster ways of doing things poorly. Highly specialized individuals are hired to help address the problem, but then instead of being able to apply their wisdom to the advertised position, they are subjugated by the few, and either capitulate and are assimilated, or leave feeling worthless and powerless to a solvable problem because of the power and greediness of just those few that try to wield their power. Many may whisper in the shadows or wish for a better situation, but instead, accept the unacceptable normal as the new normal. Soon they have no idea how to relate to what is actually the right thing, except that they believe it is wrong because it’s not what is done now.
I generally refrain from any personal statements, however today I’m going to talk about my closest experience with “Guns in America”. Some facts to start.
- The US accounts for 4.25% of the world population, let’s say 1/20.
- The US has between 40% and 50% of the estimated number of guns in the world, so almost 1/2.
- There are more guns in the US than people. Cite America’s gun culture – in seven charts
- There are more mass shootings (4 or more wounded by a gun) in 2022 in the US than days in the year
- I live just 20 minutes away from Sandy Hook. Our church has a memorial for that tragedy. Thankfull have never had to deal with the impact of gun violence..
As a parent, I could not fathom the lifelong anguish for parents of senseless deaths of their children to guns in schools or churches or supermarkets, or hospitals. It is articulated that many gun owners are responsible gun owners, so why does the gun industry, protected from being sued in the country that sues for everything, control the narrative of the safety of humans? I don’t have to be a scholar to read a document that is over 300 years old to see how a few have twisted its meaning, and control the entire population because of it, unwavering in being reasonable that things have changed in 300 years. They certainly afford all the improvements made living in our society in the past 300 years.
My neighbors own guns responsibly. They are also parents. You require a gun license, just like if you were driving a car. They are stored in a locked gun safe, just like you would with other vital possessions or dangerous ones, however this week I came to the realization that many people are not as fortunate.
This week I was at an event, where the circumstances brought me the closest to the real potential of guns in America. Skipping forward from important preamble. I was part of a subsequent conversation with brother B of individual A who asked family member C about his guns. “He has two handguns, one may be in the car (the car he left in that police subsequently arrested him in), he has two shotguns, he has a rifle, like a sniper rifle, that’s big it will be easy to find, and at least 4 semi-automatic machines guns including the AR-15″. Person B was going to collect these items, and they were not secured in any way, so the conversation was where they may be in the home. What happened was individual A wasn’t going to be even arrested, until other ex-law enforcement strongly suggested it happen. This individual was out on bail within a few hours.
This situation could have been very different. Individual A could have left feeling betrayed and returned with weapons of mass destruction. They could have just started out like that. They could have returned home to find their guns gone, and just gone and purchased more, or even possibly just borrowed others easily. I am skipping over a lot of important details as to why this was more of a close call then I am describing.
Guns in America is a complex problem, however when every single recommendation from politicians for fixing the gun problem by doing everything else except tackling the actual root cause, the gun, well that’s insanity. There is simply no other single word. When there is a press conference regarding a terrible mass shooting at a school, and not one single immediate action regarding guns is mentioned, why? My thoughts and prayers are also for all those suffering, but removing machine guns, requiring licenses, requiring background checks, raising the age, limiting the amount of bullets and magazine capacity, not allowing sale of body armor, these are all reasonable requests that still let you own a gun, just like a car. I have to provide proof of Id to buy Sudafed for a cold, but I could walk into a gun show and buy a machine gun. You have to be 21 and show your Id to purchase alcohol, but I can easily get body armor. I was forced to provide my age to buy one container cough medicine from a grocery store, yet you can buy an excessive amount of ammo more easily.
Returning to the technical analogy, it seems the gun problem is just like a technical debt problem. It never goes away, there are always ways to make the increase of technical debt easier. The priority is to add to the technical-debt not to prioritize removing it. In an organizations of 1000s, the few that try to make the world a better place, and constantly battling an ideological world view in software engineering that is well, wrong.
And the week in several images.
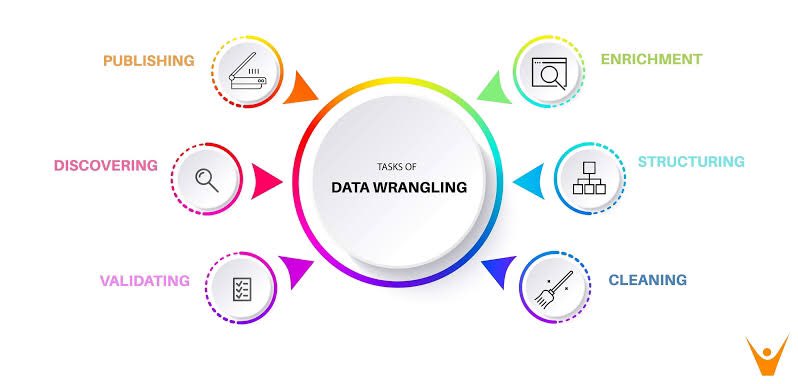
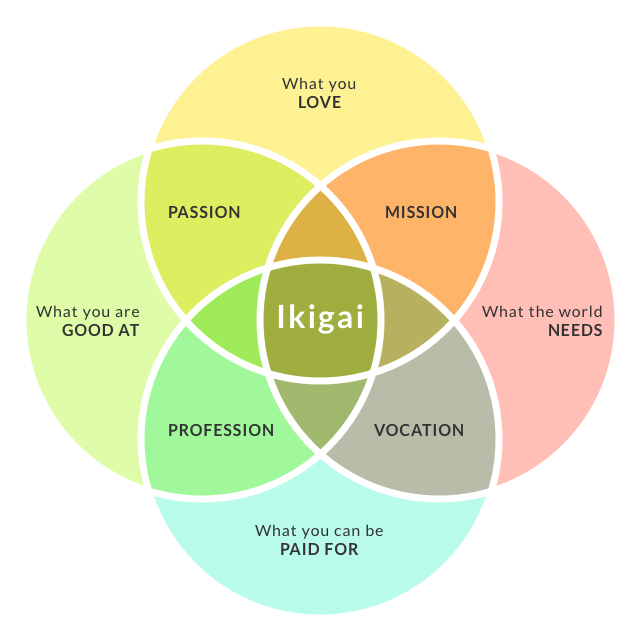
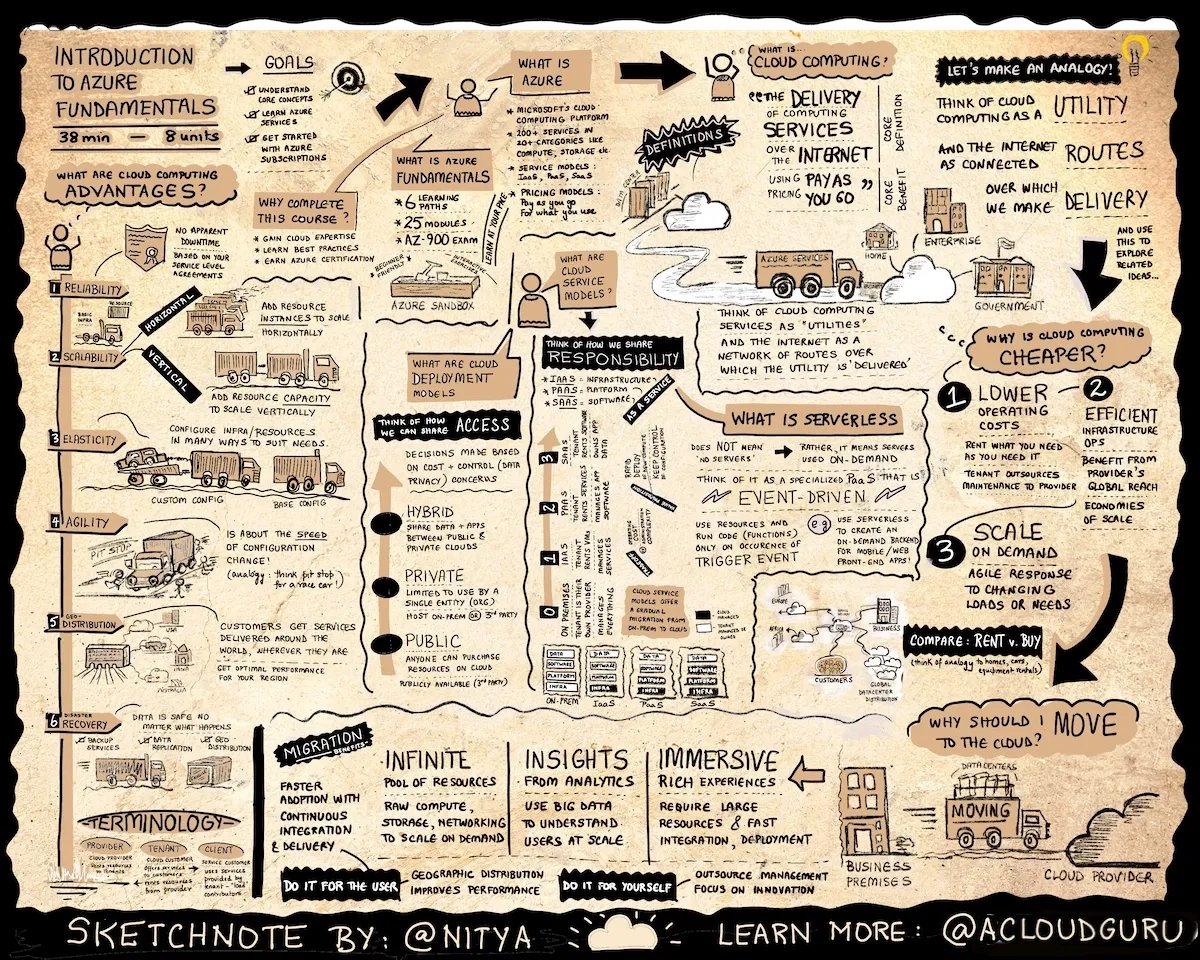
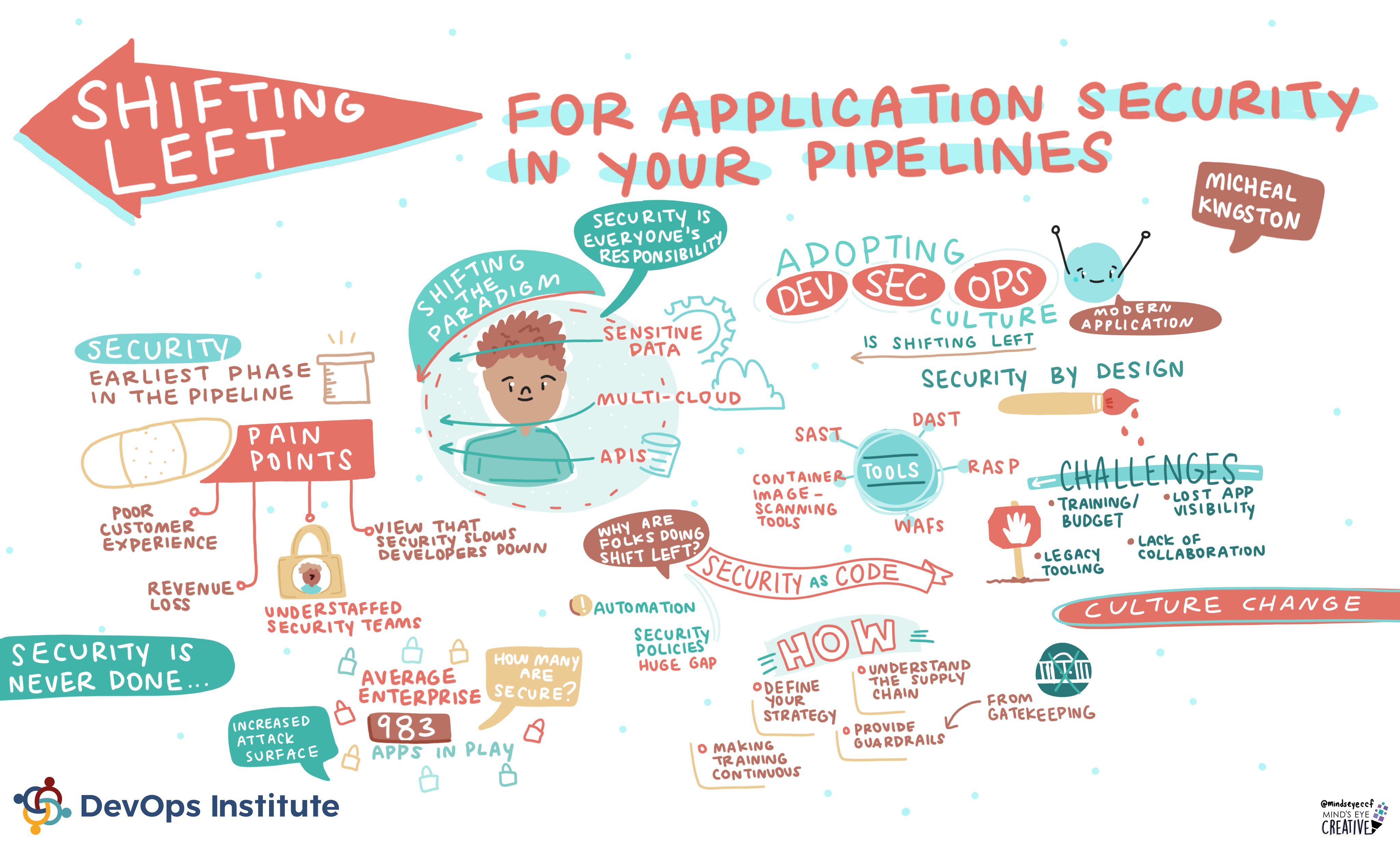
- Use python Frameworks via https://twitter.com/parvezshahshaik/status/1534899902521782274
- A better use for assault weapons, like a real war
- Thoughts and prayers are always required, but are only a small part of the larger need