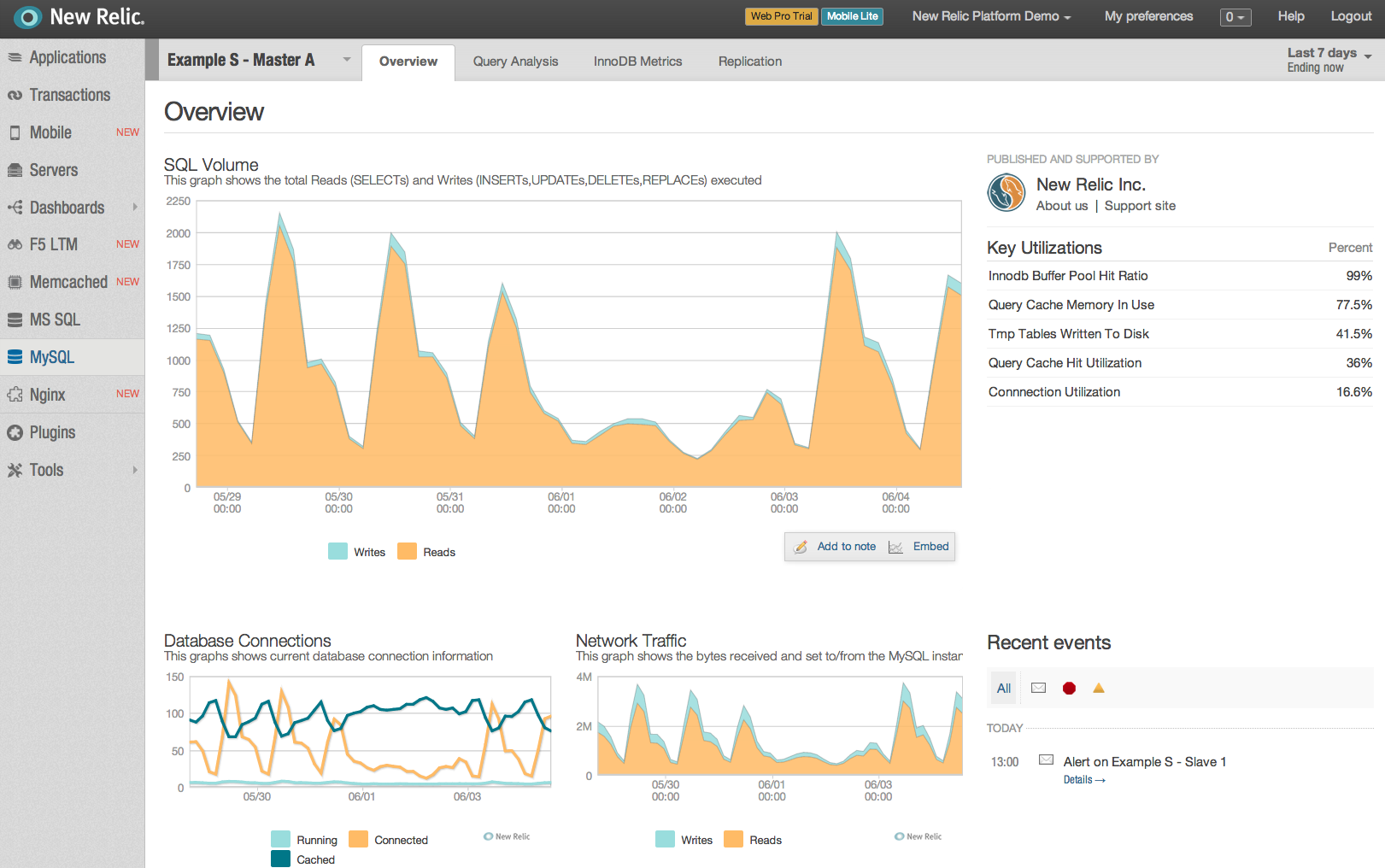
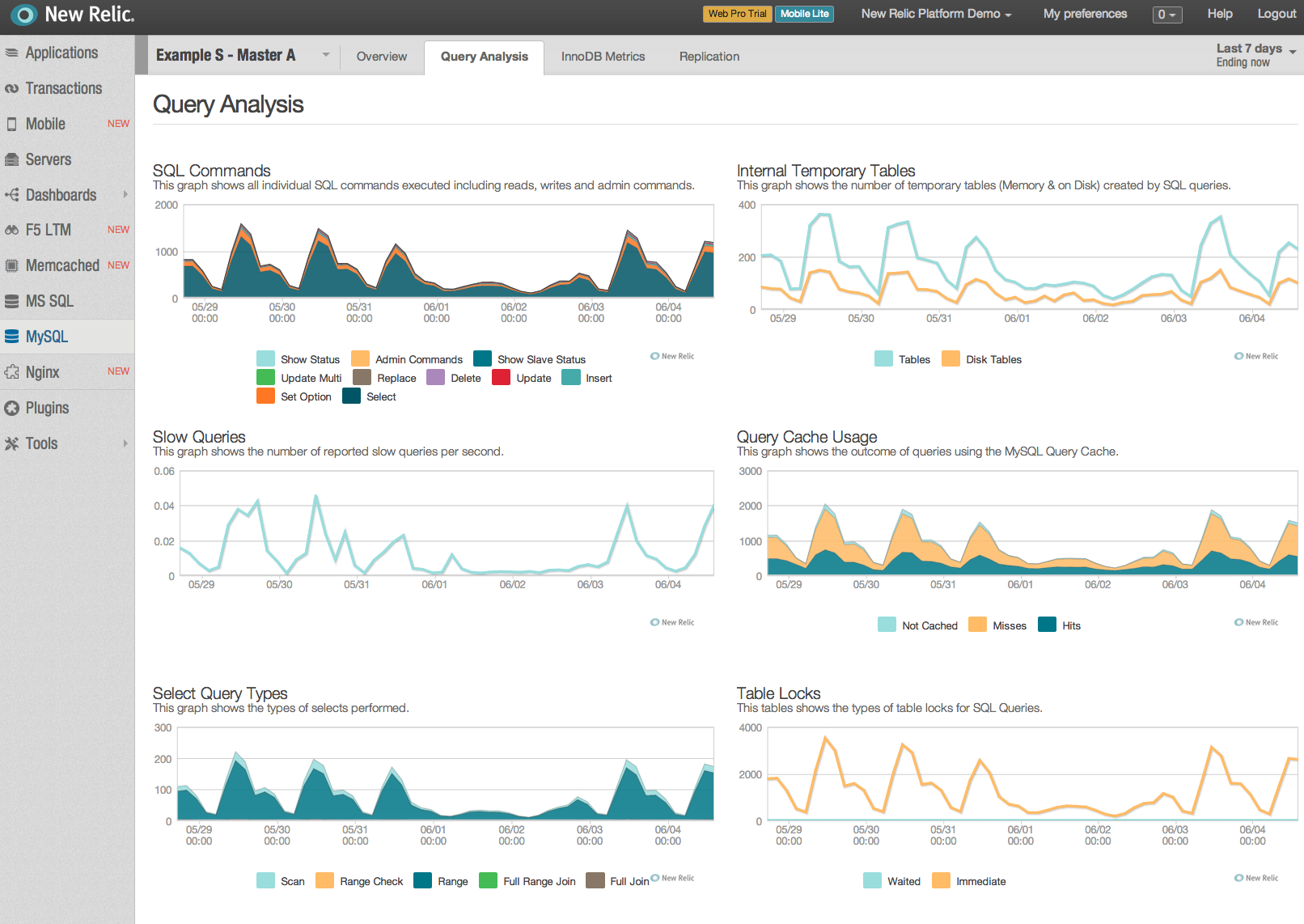
The following simple INFORMATION_SCHEMA statement will identify and also verify tables that have no rows. These may be candidate tables to remove from your data model.
mysql --defaults-file=.my.cnf -N -e "select CONCAT('SELECT "',table_schema,'.',table_name,'" AS tbl, COUNT(*) AS cnt FROM ',table_schema,'.',table_name,';') as cmd from information_schema.tables where table_schema not in ('mysql','performance_schema','information_schema') and table_rows=0;" | mysql --defaults-file=.my.cnf -N