The second MySQL tutorial session at Oracle Open World was “MySQL Group Replication in a Nutshell” by MySQL Community Manager Frederic Descamps. This is succinctly described as:
“Multi-master update anywhere replication for MySQL with built-in conflict detection and resolution, automatic distributed recovery, and group membership.”
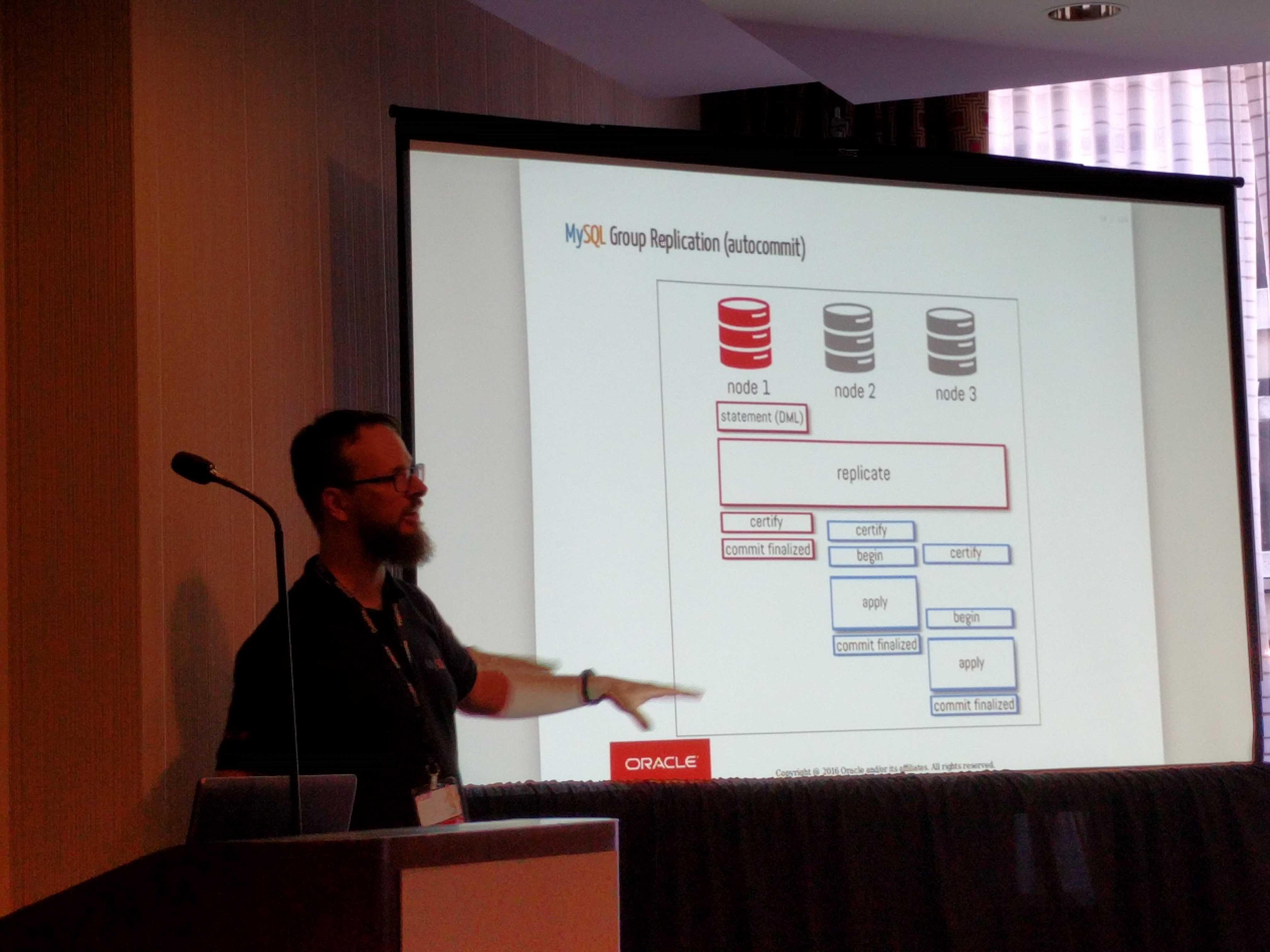
MySQL Group Replication (GR) is a virtually synchronous replication solution which is an integral component of MySQL InnoDB Cluster announced at the MySQL keynote. You can download a labs version of MySQL InnoDB cluster which includes three components.
- MySQL Router
- MySQL Shell
- MySQL Group Replication
While included as part of MySQL InnoDB cluster, MySQL Group Replication can be run standalone. It is a plugin, made by and packaged by MySQL. With the plugin architecture in MySQL 5.7 the ability to release new features is greatly reduced from the more typical 2+ year general availability (GA) cycle. Plugins also allow for functionality to be not enabled by default therefore preserving the stability of an existing MySQL instance running version 5.7. This is a change in the philosophy of new functionality that I discussed in Understanding the MySQL Release Cadence which in 5.7.13 introduced the SQL interface for keyring key management. Not all in the community are happy however I consider it an important requirement for time-to-market in a fast paced open source data ecosystem.
MySQL GR is based on Replicated Database State Machine Theory and uses Paxos for evaluating consensus of available nodes in the cluster, being referred to as the Group Communication System (GCS). This is one key difference with Galera as the Paxos approach relies on accepting the certification stage within the cluster after a major of the nodes have acknowledged, rather than all nodes. MySQL GR is supported on a wide range of platforms including Linux, Windows, FreeBSD and Mac OS X, another difference with Galera.
The current Release Candidate (RC) version of MySQL Group Replication has some required configurations and some situations for applications that may not be ideal use cases for a synchronous solution. There is the complexities in the migration process of any existing infrastructure to considering MySQL Group Replication, which has at a minimum requirements of MySQL 5.7, GTID’s and row based replication. I would like to see MySQL put a lot more effort into the education and promotion of MySQL migrations from older versions to the current MySQL 5.7. Ideally I’d like to see better tools starting with MySQL 5.0 which I still see in production operation.
Some things are just the impact of current development priorities. The shell does not offer a means to promote a master in a single write configuration, i.e. the only way to simulate a failure is to produce a failure, which really means your three node cluster is no longer highly available. The use of savepoints is not currently available, a needed feature for future full compatibility for use in an OpenStack deployment. The creation of a cluster via the MySQL shell requires you to make the decision of supporting multi-master writes or a single master write. I can see the ideal need to be able to better support large batch transactions and DDL (some of those edge cases) to be able to toggle to a single write master and back. The current workaround is to utilize MySQL router to simulate this use case. The MySQL shell greatly reduces the complexity of orchestration. One of the features I like is a very convenient means to validate an Instance to see if the configuration matches minimum requirements. For example:
$ mysqlsh
> dba.validateInstance('root@mysql3:3306')
...
ERROR: Error executing the 'check' command: The operation could not
continue due to the following requirements not being met:
Some active options on server 'mysql3@3306' are incompatible with Group
Replication.
Please restart the server 'mysql3@3306' with the updated options file
and try again.
Option name Required Value Current Value
Result
------------------------------- --------------- ---------------
-----
binlog_checksum NONE CRC32 FAIL
master_info_repository TABLE FILE FAIL
relay_log_info_repository TABLE FILE FAIL
transaction_write_set_extraction XXHASH64 OFF
FAIL
at (shell):1:4
in
Something you can now do dynamically and persist in MySQL 8.0 using the SET PERSIST syntax.
The overall setup in a greenfield application is reasonable clear and will improve as the product moves towards general availability. The MySQL shell has a lot of future potential in a number of administrative functions, and the ability to switch easily between JavaScript and SQL means you can get the best of multiple languages.
In subsequent posts I will look into more of the detail of setup and monitoring of a cluster with performance_schema. I hope that existing monitoring tools will also start to support monitoring Group Replication. As the author of the New Relic MySQL Plugin in 2013 I may need to get motivated to offer a SaaS solution also.
You can find more information with official blog posts on MySQL Group Replication.