Everything you need to know about seed funding for startups
A recent call with a startup founder funded by TinySeed led me to learn about MicroConf and Rob Walling. (Thanks Tony for the info). This has led to a lot of great info in several new newsletters and videos including this video. A few very valuable tips I learned included the answer to Why should you raise funds at all? The 1-9-90 rule, and different types of funding including Indie funding. It was interesting to find out that the TinySeed accelerator is 1 year, and not 13 weeks, which is common in NY. Rather than sharing my notes, go watch the video.
5 Books That Paved My Path to Entrepreneurial Success
I have not heard of any of these books, and I have such a long list, perhaps I need to publish my list and elicit feedback on prioritizing. The list from this article is as follows:
- 1. Mastering negotiations with never split the difference
- 2. Embracing risk with skin in the game
- 3. Building habit-forming products with Hook
- 4. The roadmap to a billion dollar app in How to Build a Billion Dollar App
Visualization
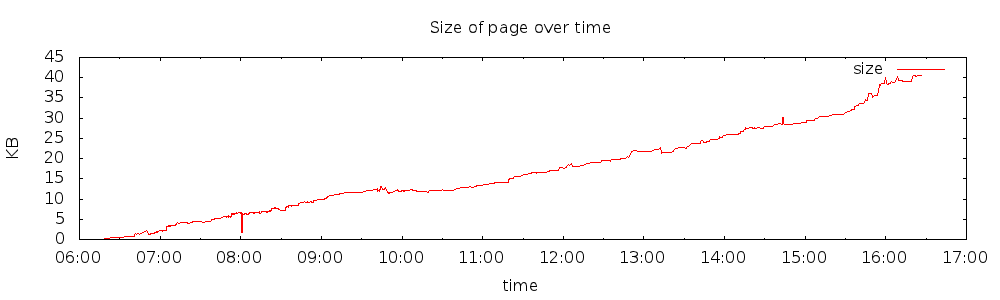
Last week I was at two events in Brussels. I chose to head to London to fly home. I found this map present in many tube stations (The tube is the London Metro Subway). It’s been a decade since I was in London, and over two decades since I lived in the UK. I found the new map great. When I mentioned it as a good visualization, I was surprised that locals of the London area thought it was horrible. I saw the value in the visualization, but perhaps others see it like art, “in the eyes of the beholder”. It could also be “habit”.
Cats and Dogs
How many *NIX `cat` memes can there be? Well, a lot cat is the most misused thing by programmers new to Linux. I cringe every time someone uses it wrong in a bash script. Thread below with proper uses of cat only.
Hey, dogs, you are in the count also with HTTP STATUS DOGS. My picks are 300 Multiple Choices, and 429 Too Many Requests for me.
Upcoming Events on my radar
- Starting today Feb 14 2024 is the ScyllaDB Summit 2024, more on that next week.
- Aiven Live in New York City on Feb 28, 2024
- Open Data Science Conference. I had not heard of this before and I’ll not be attending in Boston in April.
About “Digital Tech Trek Digest”
I take some time early in the morning to scan my inbox newsletters, the news, LinkedIn, or other sources to read something new covering professional and personal topics of interest. Turning what I read into some actionable notes in a short, committed time window is a summary of what I learned, what I should learn and use, or what is of random interest. And thus my Digital Tech Trek.
Some of my regular sources include TLDR, Forbes Daily, ThoughWorks Podcasts, Daily Dose of Data Science and BoringCashCow. Also Scientific American Technology, Fareed’s Global Briefing, Software Design: Tidy First? by Kent Beck, Last Week in AWS to name a few.
Random
I shared with a colleague on Feb 9. “3 SQL databases walked into a NoSQL bar. A little while later, they walked out because they couldn’t find a table.”






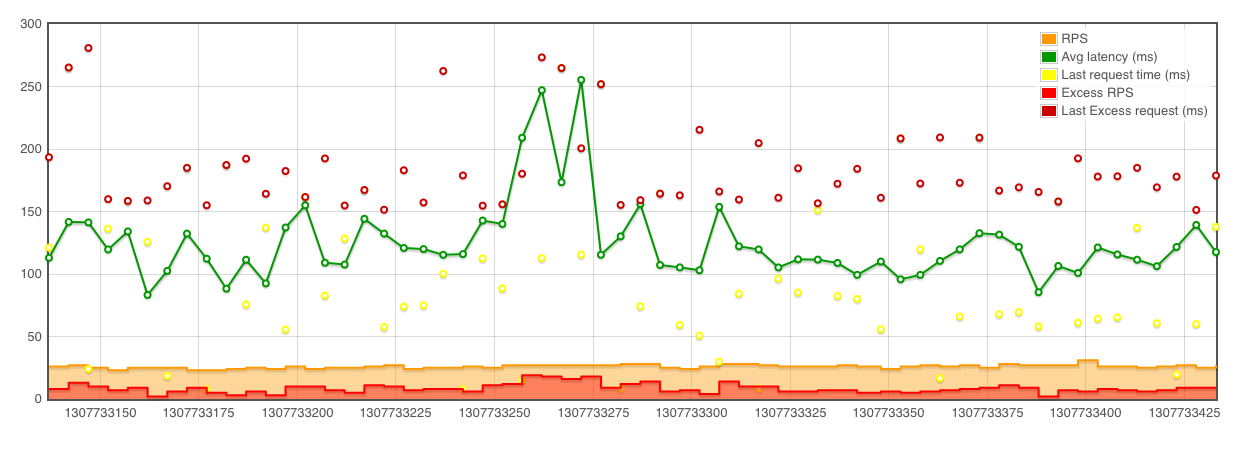
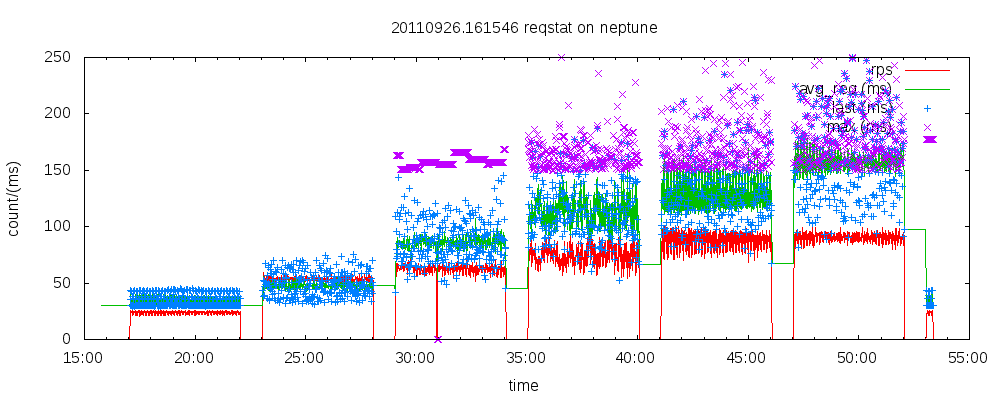
 At the closing keynote of the recent
At the closing keynote of the recent