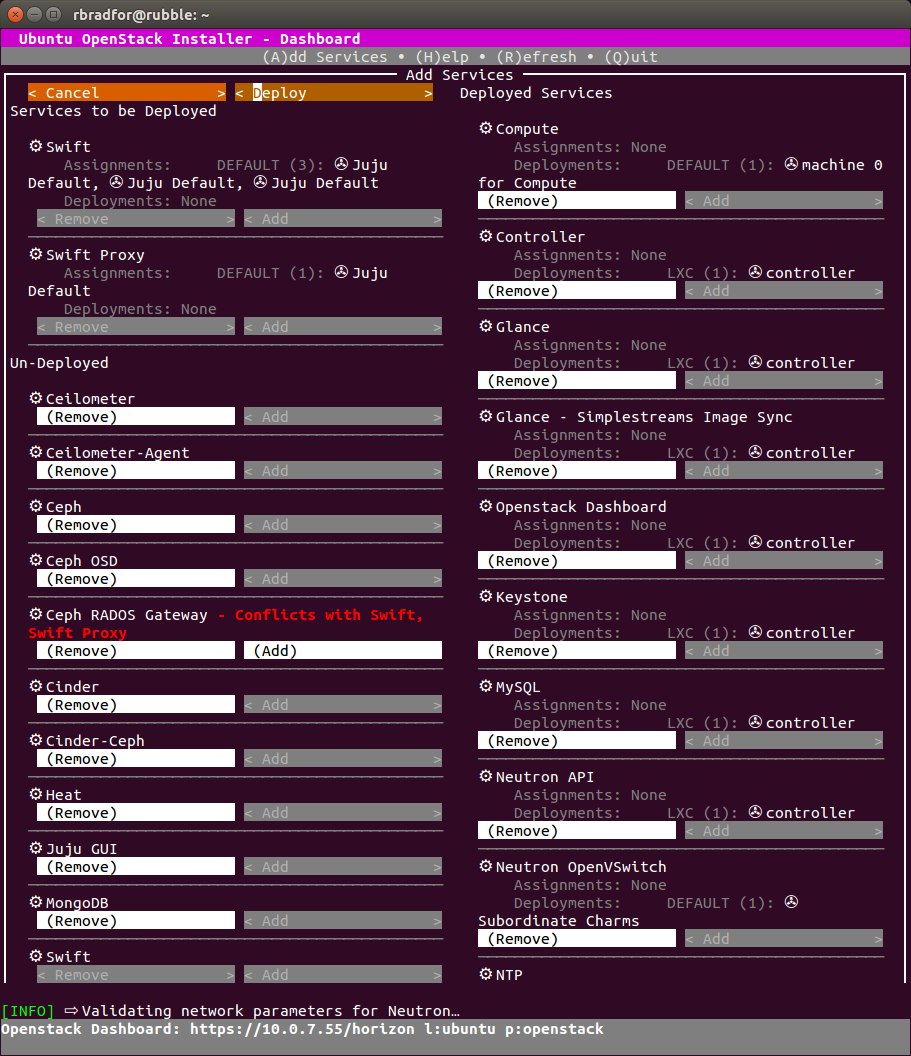
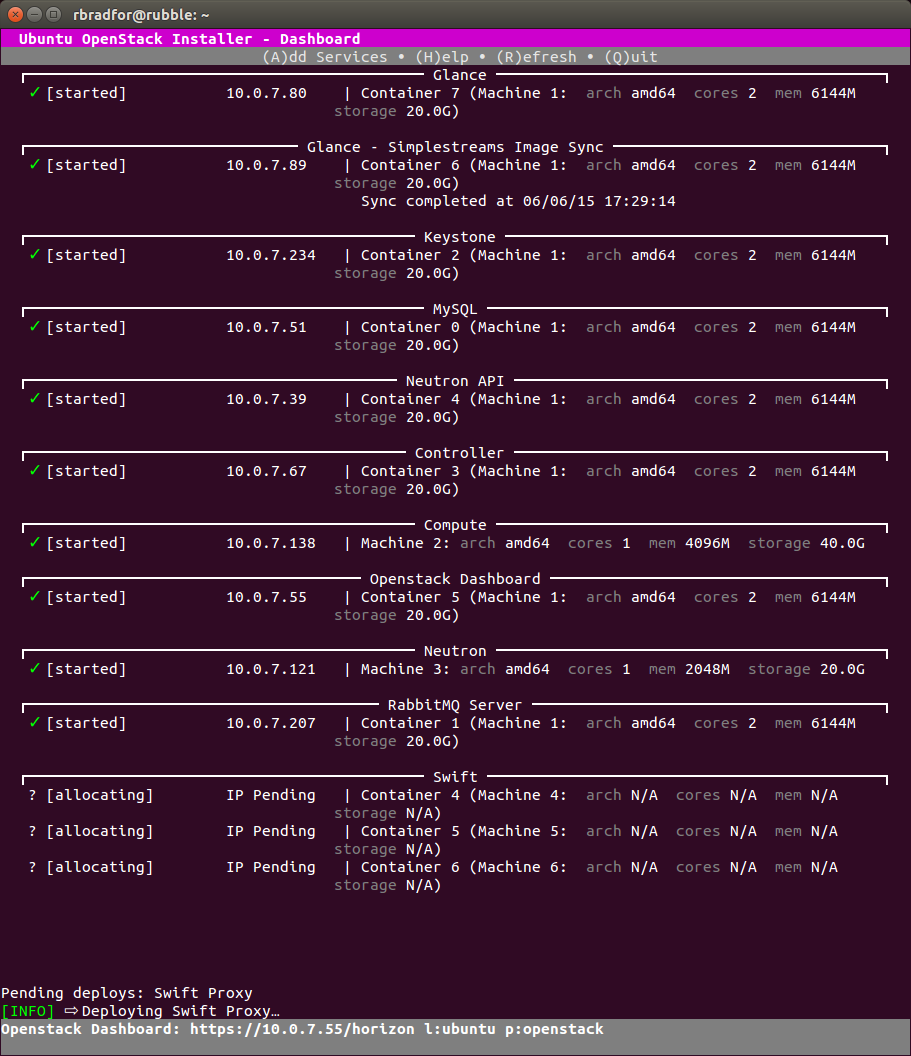
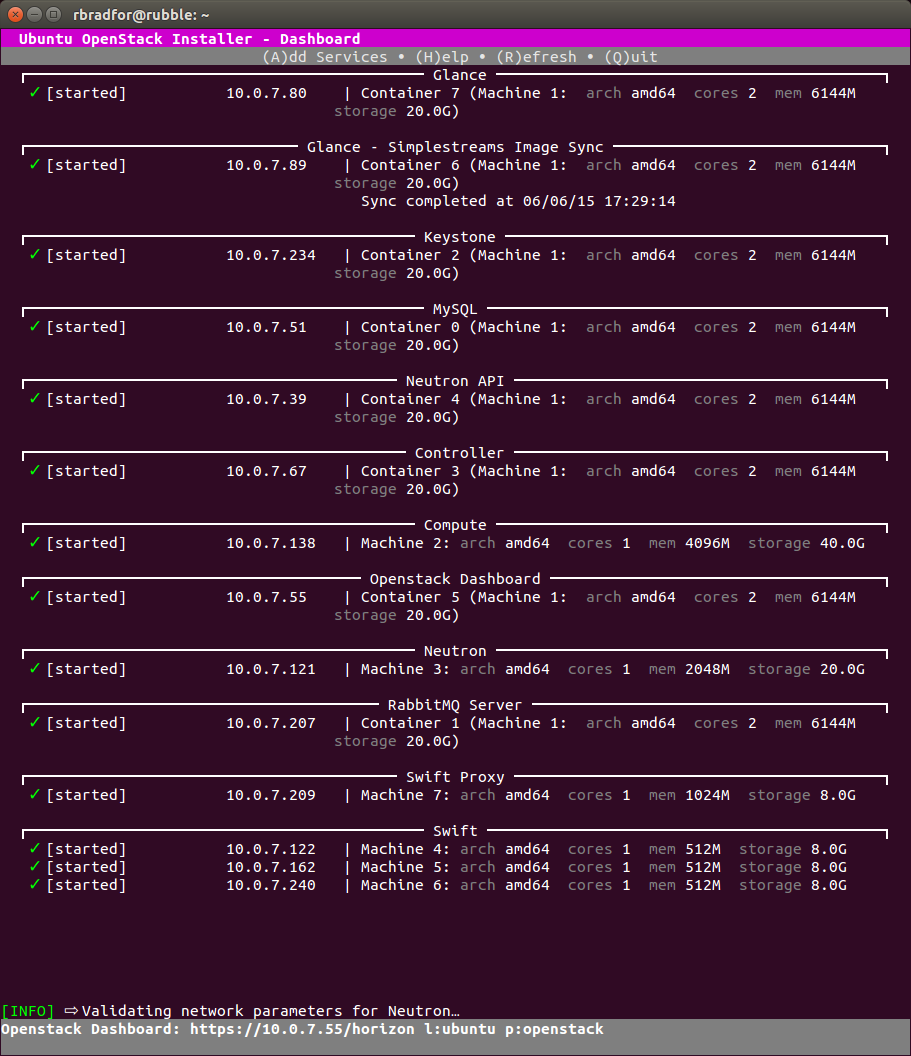
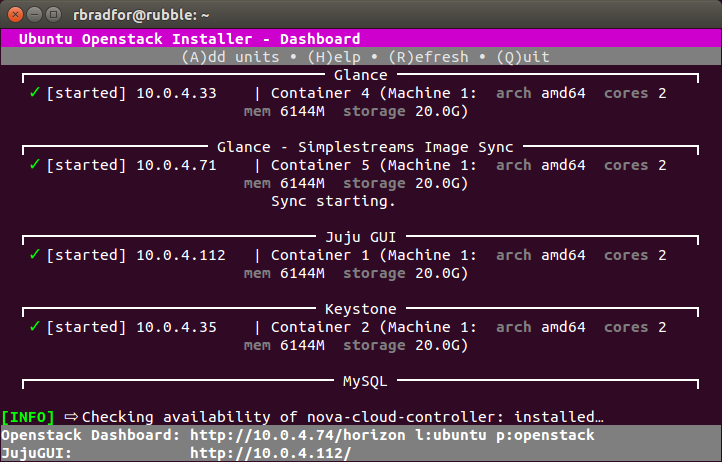
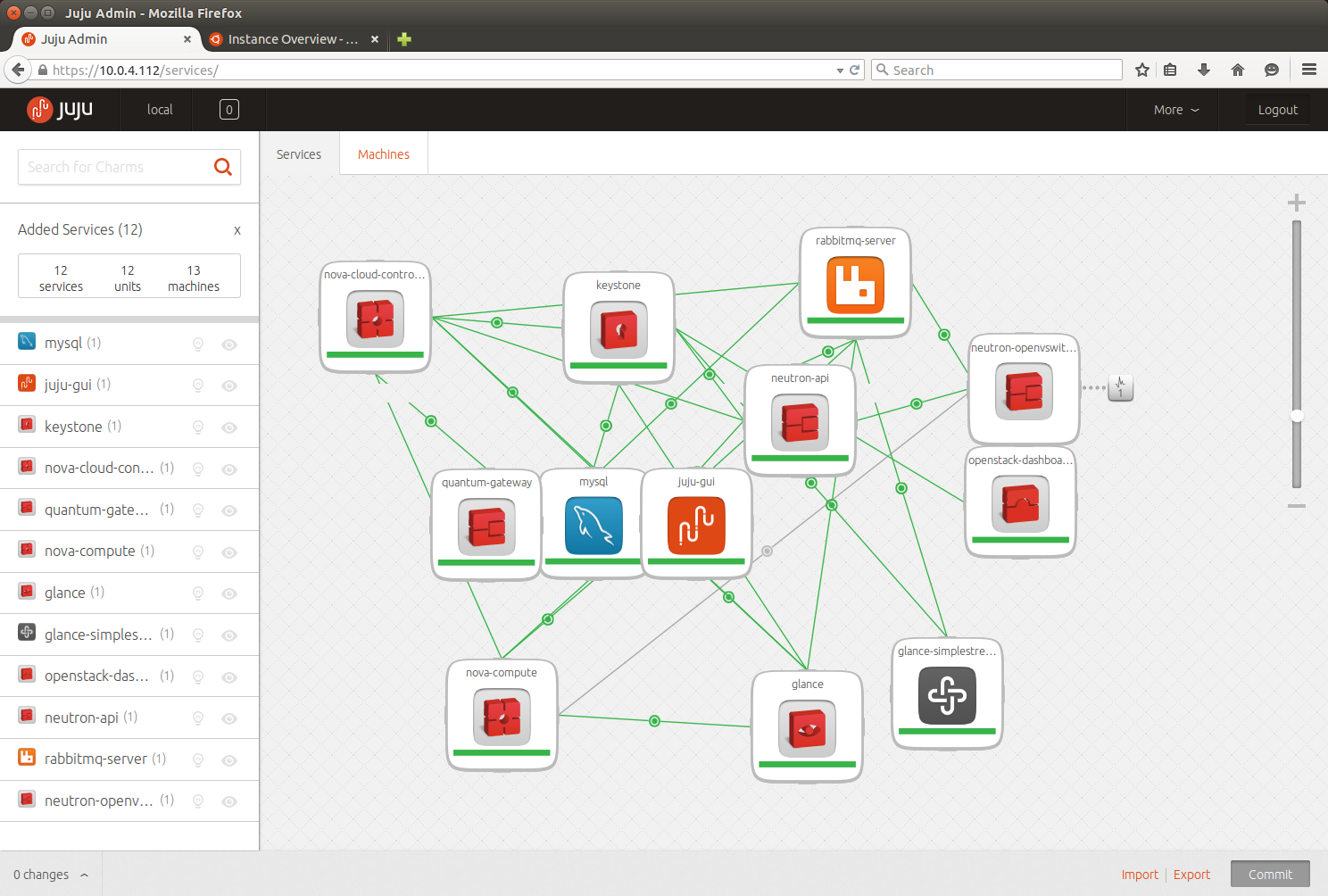
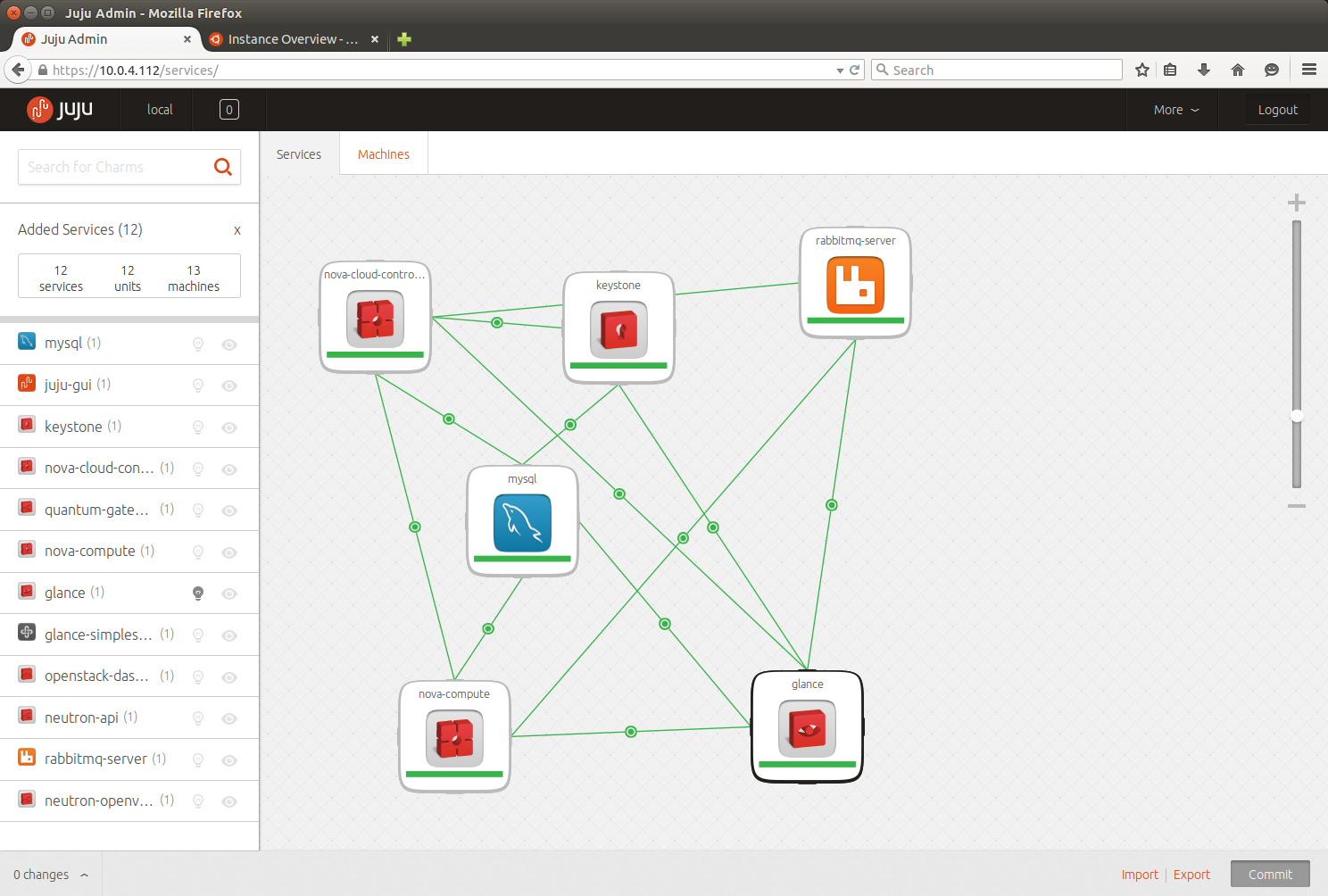
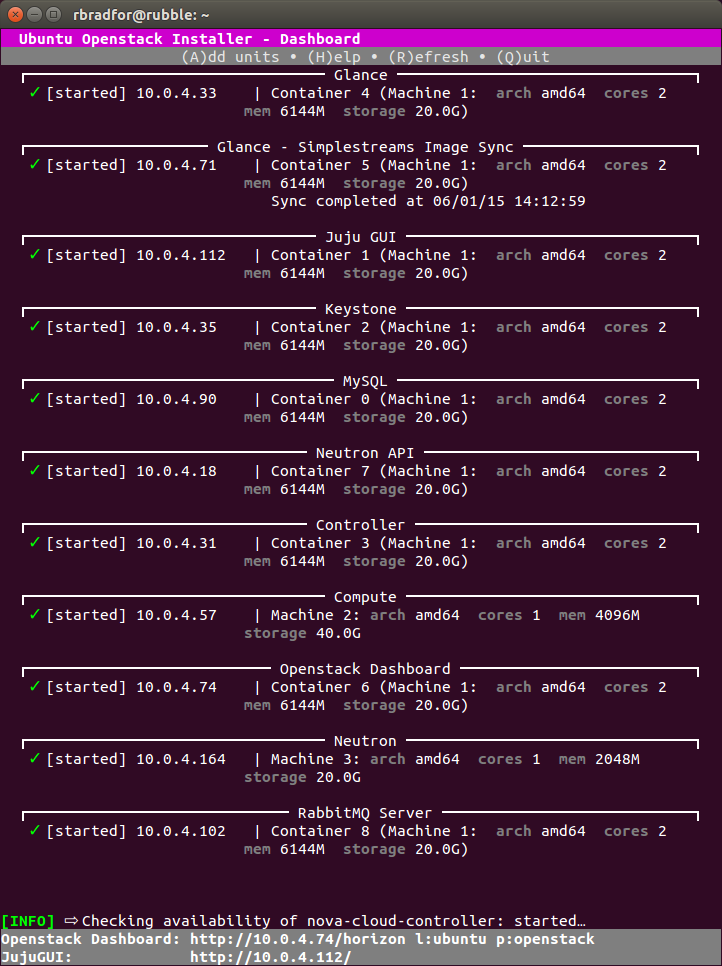
Giuseppe Maxia has provided some great MySQL docker images. Percona and MariaDB also provide version via Docker Hub. In an attempt to have a consistent means of launching these different images I created the following convenience functions.
- Install docker for your OS. See Official Docker installation instructions.
- Get dockerhelper.sh
- Run your desired variant and version.
$ wget https://raw.githubusercontent.com/ronaldbradford/mysql-docker-minimal/master/dockerhelper.sh $ . ./dockerhelper.sh Docker Registered functions are: docker_mysql, docker_percona, docker_mariadb $ docker_mysql ERROR: Specify a MySQL version to launch. Valid versions are 5.0 5.1 5.5 5.6 5.7 8.0 $ docker_percona ERROR: Specify a Percona version to launch. Valid versions are 5.5 5.6 5.7 $ docker_mariadb ERROR: Specify a MariaDB version to launch. Valid versions are 5.5 10.0 10.1