The eXtreme Programming (XP) methodology places emphasis on a number of core principles for agile software development. These include (and are not limited to) the planning game, short and frequent iterations, testing, frequent refactoring, continuous integration, ownership and standards.
Identifying the problem
These core principles however are not the full lifecycle of software development. This is really only a portion of the lifecycle. What is lacking is the definition for the ongoing responsibility and ownership by the creators of software in the sustainability of said software for the lifetime of use and benefit to an organization.
An agile methodology approach (of which XP is just one) fails to expose and describe the full operational cost within development, testing and deployment. Just as a single line of code is viewed a hundred times more than the time is was written, the usage of that code in the full lifecycle of an organization is potentially a magnitude more investment of time and resources.
Software development is not just about new feature creation. It is also ensuring full product ownership and responsibility consistently. It is also ensuring that in a larger organization, compatibility and consistency can occur with other products. In other words, it is thinking of software for the whole organization, rather than the sum of individual parts.
Scheduling lifecycle management time
Development and engineering resources already apportion time between planning, development and unit testing. There needs to be a second more important consideration. An apportionment of time between product features, product stability and product maintainability.
A good assignment of time to cover the full lifecycle adequately is:
- 60% of time to feature design, development and product support (i.e. bugs)
- 20% of time in stability and sustainability management of the existing technology stack (i.e. refactoring and testing)
- 20% of time in overall lifecycle management of delivered functionality (i.e. ongoing ownership)
Conveniently this Pareto allocation can be seen as 80% for development time and 20% for time generally considered operations.
Sustainability Management
Remember the core principles of XP that included frequent refactoring and standards. How much time is spent on refactoring code to provide a better, more consistent, more testable codebase for an application after code is initially deployed? What about across multiple applications in your organization. Engineering resources rarely invest any time let alone actively scheduling time for code maintenance by the entire engineering organization, yet there are immediate benefits. It can be amazing how more performant a system is when unnecessary code is simply deleted from software that has gradually evolved over time. The compounding benefits can mean less code to view by developers and thus adding incremental efficiency. Less code to deploy also means smaller installation and application footprint. Particularly when the code is unnecessarily executed in the common usage path.
Engineering teams in general are more focussed on delivering new functionality or fixing issues with newer functionality rather than reviewing existing functionality for optimization, consolidation, replacement or removal. What about applying an improvement to not just one application, but multiple applications across an organization whenever possible.
There is generally at least one individual at each organization that has the attitude of “Do I write the line of code, or is there a better way?”, and “What code can be deleted as it is no longer (or was never) used?”. If all engineers considered, evaluated and implemented these concepts as a daily process, code would be more stable, it would be more lean. Does your organization have a recognition for the developer that has deleted the most lines of code from your production system?
The following is the example of a single developers improvement to a production system via deletions.
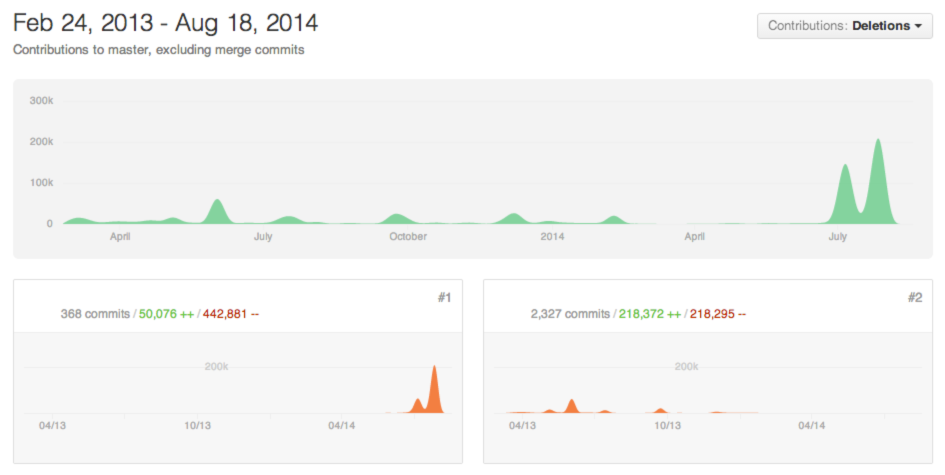
Are there better ways of implementing functionality with the version of the technology stack already in use? Many times a newer version of software is used for one feature, but what other new or improved features also exist. This is a proactive measure to look at the features of the technology in use. This is a different type of refactoring, but the same concept in code reduction. A great example here is the use of an iterator design pattern rather than a loop. In initial deployment of an application, memory optimization may not have been obvious, however over time and increasing datasets this simple proactive action has a larger benefit for the application.
A final step in improving sustainability of the software is testing. An agile approach introduces unit testing, but testing do not stop with the validation of a single line of code. Testing encompasses how that functions with the entire system, often known as functional testing. Systems often require load testing to know the capacity before failure, not after it occurs. If as much time was spent in these two additional areas of testing, as was spent in unit testing, more robust systems would exist and the unseen benefit is the productivity to spent more time developing.
Here are a few customer examples of refactoring. Unfortunately this is an all to common occurrence.
Module bloat
An assessment of the technology stack for a newly deployed application (i.e. just a few weeks old) showed a long list of PHP and Apache modules. Without any justification as to why these modules were used, and without a willing engineering sponsor it took quite some time to first produce automated deployment duplicating this custom environment, than applicable testing to strip out what was ultimately unnecessary. The overall outcome had multiple effects. What was needed to operate the system was actually documented. What was needed was actually automated to assist in future deployments. The resulting software was more performant as it had less baggage. The resulting deployed VM image was actually over 1GB smaller after all bloat was removed. This improved the time to deploy new application servers. As this system had a very large scale up and scale down weekly, we are talking 1000% at peak times, the impact of a more lean stack had a huge impact on the true deployment times of the application. This is an attribute that can be difficult for developers to appreciate, when comparing a development environment to a production system.
This entire process and the large investment of work would have been almost non-existent if this was part of the engineering methodology used during initial development (which took over one year for initial deployment), and if more (or all) individual developers stopped to ask why are we adding additional modules. This is part of the infrastructure planning that should have a feedback loop within each iteration. This also requires both a solid experience in engineering and architectural oversight to be able to estimate the impact over a much larger time period than the development cycle.
Framework bloat
An education based client faced a huge problem. The existing system had grown over a number of years, the engineering department had grown from one developer to over a dozen developers, yet the approach towards software development had not changed from that single developer original module based Drupal approach for a small application. With sales for the next annual education cycle already 4x more than the current user base that was having regular outages, the system could not (and would not) sustain known future sales.
Often the first question asked by clients in this situation when offering performance services is “How can I scale my system 10x?” I generally counter this question with “How did you scale from when your system was 10x smaller to now?”. Aside from the interesting conversations around these responses, I often need to explain that performance is about efficiency, and this often requires a cultural change. I also generally quote one of my popular lines — “When reviewing the performance of a piece of code (or SQL statement); the first objective should not be to make it better; the first objective should be to eliminate it.” This is also generally received with blank stares and silence. Efficiency it seems perhaps is no longer taught or practiced.
As with most simple yet profound assessments an example of the clients production system can best demonstrate what inefficiency is. An analysis of the user registration process unveiled alarming result. This analysis that can happen in a very short period, e.g. an hour. In summary, 50 SQL statements were executed to register a new user to the system. A physical desk check (again foreign when you have to ask multiple people how do I print out something as a visiting consultant) of just the database access showed that with the present inefficient Drupal ‘node’ schema design, just 11 SQL statements were actually needed to complete the required task. That is, the code could be 500% more efficient and nothing has been tuned or scaled. The client needed at least a 400% immediate improvement. However, just explaining this did not convince the organizations c-level executives to reset poor development practices to addressing immediate and ongoing scalability (i.e. success of your startup). They wanted a more abstract approach, they wanted a magically sharded solution were simply throwing H/W (and $) at the problem made it go away without changing the engineering mindset. If you go back to the answer to my response question you find this is often the solution to get to the current point, that is add more servers, add caching, add read-only data access. This is not actually the solution but is adding complexity to the problem and making it more expensive to correct. In the startup ecosystem this is also known as a successful catastrophe. You reached all of your marketing and sales pitch goals, and your software crumpled under your unplanned success.
Was this problem just in user registration, or was it throughout the entire application? If looking at one common and frequent code path a 500% improvement can be made with 0% feature impact. Would that not indicate the problem exists elsewhere in the codebase. In fact, this example product was not even the classic RAT v CAT that is often a more compounding performance issue.
Further assessment of this one code path demonstrated that when an optimal schema design was architected for the purpose of the application, the number of SQL statements would be reduced to 5 (i.e. a 900% improvement). This is a significant performance and scalability benefit when using applicable architectural design and strategic planning. Performing regular architectural reviews by skilled resources in your business strategy can help to address development productivity regression long before they occur. A great architect never sees the true benefits of their work. It is a silent reward that their given experience, knowledge and expertise has an unknown financial value to an organization.
Lifecycle Management
It can be difficult to understand the impact of code in the full lifecycle of a software product in the 21st century. Until individuals have seen the birth, growth, support, longevity and death of a system it can be impossible to understand the impact some lines of code have with one application and the interoperability requirements with other applications. When the waterfall approach for SDLC was still in active use this was possible with large scale projects over time. In the post tech boom age and with the use of agile methodologies the incremental development lifecycle hides a lot of important context for better assessment of true cost savings.
The introduction and increasing popularity of the devops and site reliability roles also attempts to hide what many large organizations and successful website have, that is a dedicated operations team. Tools have done so much to enable engineers to be more productive. Automated provisioning, PaaS and CI/CD tools seamlessly enable more (abstract) code to be written to provide that essential functionality to the end user. Automated testing has replaced design documents. Organizations developer systems without is a data model? All of these tools and techniques however do not replace the intelligence needed to operate a system over time, particularly for tasks including upgrades and integrations.
One simple concept can be implemented to assist in all contributors owning lifecycle management.
The first is the responsibility of a developer being paged when a production problem occurs due to the line of code they wrote. Being responsible accepting that in the early morning or weekend you may be needed to address a problem attributed to your individual work and a failure within an entire system may make the decision to consider the larger impact more prevalent. This is taking the XP principle of ownership and defining the time dimension to a period infinitely greater than the present iteration.
The following is a great tweet that shows this developer has heard of commenting their code, but not considering lifecycle management?
// When I wrote this, only God and I understood what I was doing // Now, God only knows
Justifying the reallocation of time
In the 1990s the concept of adding a quality step to software development via means of code reviews and automated testing was seen as an impediment to productivity. This potential cost in lost productivity could not be justified. Why would developers write tests when there is an entire QA team to test new features each time the software is released? Today it is seen as an essential component for continuous integration and delivery and the testing is designed to test all functionality repeatedly, not just new functionality.
Assigning 40% of present development time elsewhere could be viewed as a loss of productivity because today projects do not have a start and end date and deliverables where a total cost of ownership could be more clearly calculated. Today, projects are a continual ongoing evolution, even the concept of cost projection simply does not exist and therefore could be stated as impossible to validate against. After more than a decade of working with startups at many stages of evolution, the cost of not undertaking stability and lifecycle management is a far greater longer term cost to an organization by an outside observer. Look no further than the much larger turnover of technology staff in today’s organizations. These resources have institutional knowledge that is lost to the organization. This information is rarely documented as a historical artifact and the reason why steps were taken cannot be inferred from what is presently the state of the current code (or even reviewing the code revision history). This cost is rarely calculated within the software development lifecycle.
Adopting ownership
Many organizations suffer from the clash of traditional infrastructure principles with the pace of accelerated innovation. This approach helps to better balance the responsibility particularly between engineering and operations departments and improves the workflow to producing better products to the business in the longer term and ultimately to those who matter, the customer.
When developers value the total impact of a line of code in the full lifecycle of the product or service, a different mindset leads to actually writing better code. This code results in being more efficient and the carryover effect is the developer is actually more effective at writing more subsequent code.

 I have successfully with a number of systems, specifically CRM implementations used a Cartoon Environment for the sample data. There are a few reasons for this. First, most people I’ve ever met can related in some way to some set of the data. If they can’t, then there can read info online, or watch a movie etc, and get an appreciation from the representative data set, effectively I’m leveraging of the time and effort of others here, much better then a non-descript set of data.
I have successfully with a number of systems, specifically CRM implementations used a Cartoon Environment for the sample data. There are a few reasons for this. First, most people I’ve ever met can related in some way to some set of the data. If they can’t, then there can read info online, or watch a movie etc, and get an appreciation from the representative data set, effectively I’m leveraging of the time and effort of others here, much better then a non-descript set of data. In an
In an  Well if the weight of the book has anything to do with it, it’s the lightest Java book I’ve got.
Well if the weight of the book has anything to do with it, it’s the lightest Java book I’ve got. 
{kind=link}