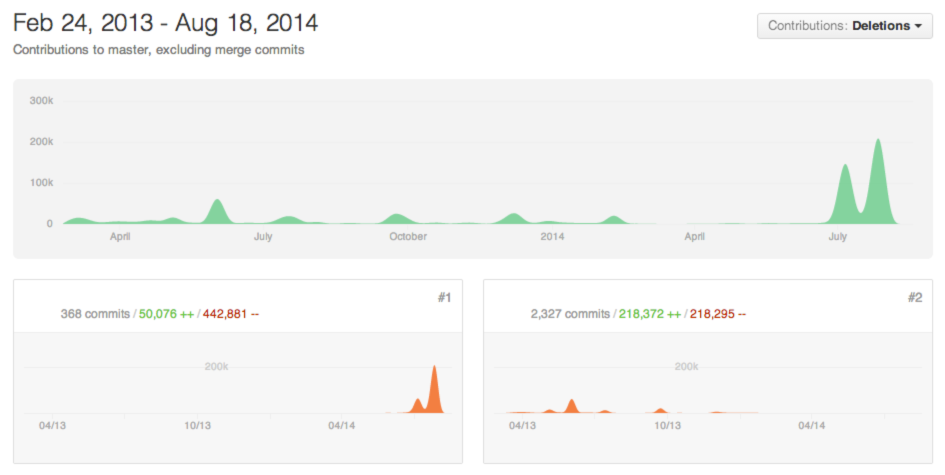
Organizations are rapidly developing new software applications to meet the need to consume ever increasing digital content and maintain market share in a given field. These newly developed applications cover a wide range of needs from advanced data analytics, to mobile applications, to personalized recommendation engines. They utilize a new generation of languages, tools, frameworks, design approaches and software engineers to iterate rapidly. Many applications are being created without the foresight of the ongoing lifecycle management that is needed to manage this explosive growth. Organizations with existing information systems will need to support and integrate these products to maintain business viability.
The view of applications today in a typical larger organization that has started to adopt new services may look like:
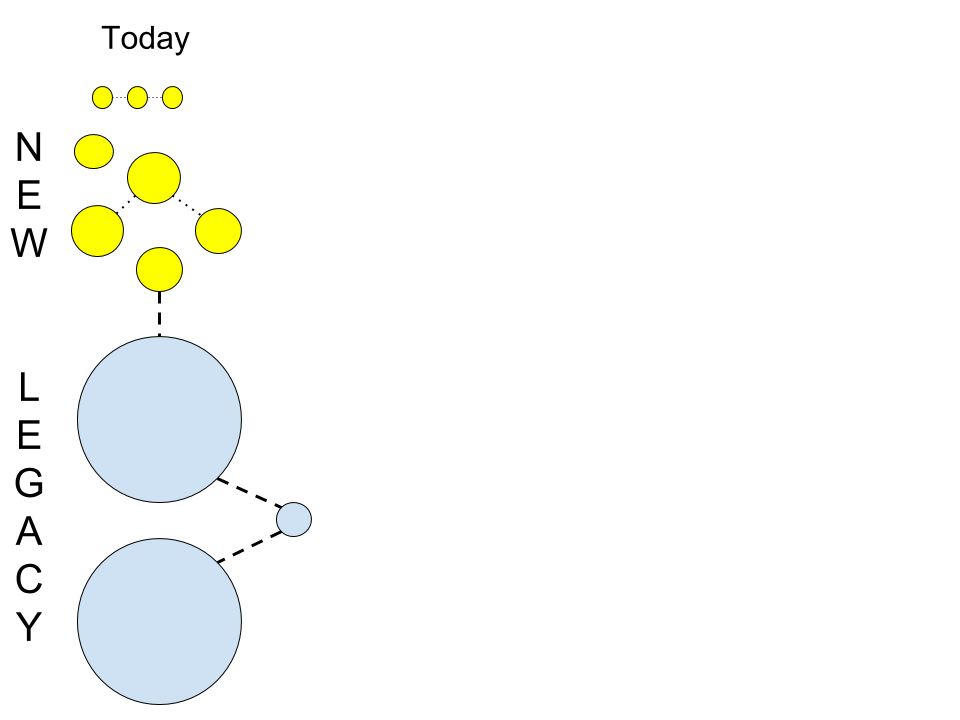
Like many pictures, this is just a snapshot. It does not represent what happens when you include the dimension of time.
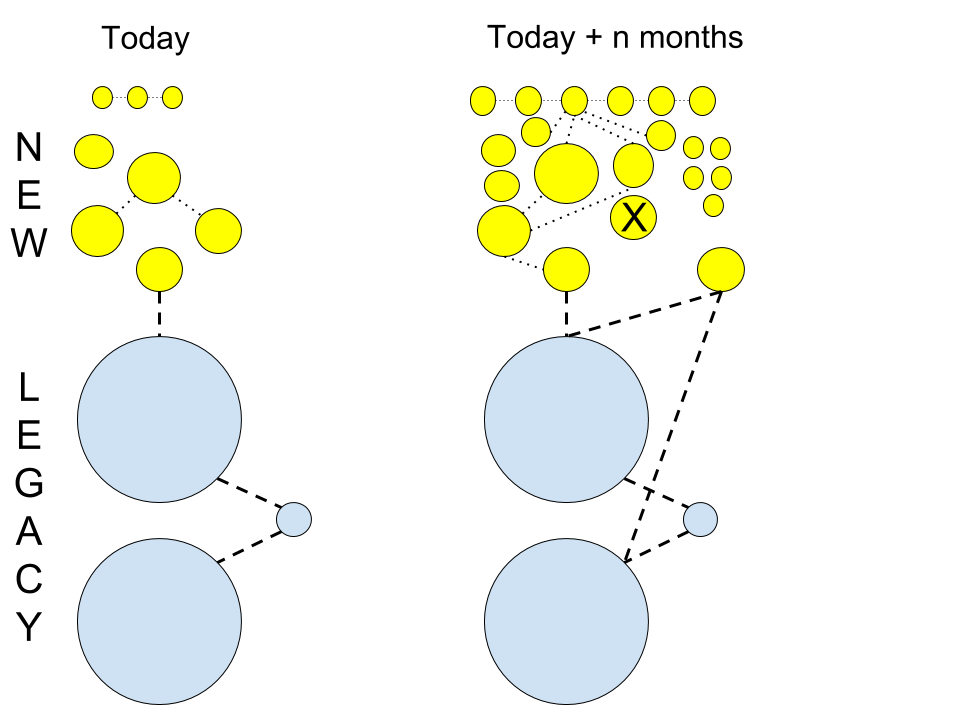
Regardless of the amount of time that passes between these two snapshots, what is important is the pace of development, i.e. the rate of change. If the goal is to replace a legacy system, the work on replacing the legacy system has to match and exceed the velocity of new development.
The legacy dilemma is a needed integration in many organizations. Established monolithic applications contain great data wealth. Organizations that are not integrating are not leveraging some of the greatest assets available.
There are a number of reasons why legacy applications are considered for replacement. The cost of licensing commercial software, the cost of running and supporting older hardware, the physical size and location of equipment, the decline and availability of skilled resources in older programming languages. What is important is to identify the strategic decisions why, and develop a roadmap that has the time, money and resources assigned to enable success. Organizations think and act in the intention of replacing legacy systems, but the plan rarely includes the detailed roadmap to completion. Solutions such as implementing a private cloud Infrastructure as a Service (Iaas) is a platform to support a system, not a plan to implement a migration or replacement.
Legacy applications fall into several broad categories. These include:
- The purchased packaged application where customization is very limited and modification is not possible.
- The third-party supported application where customization is very expensive and very time consuming.
- The in-house application that while providing core features, is not actively developed. It may appear too complex or fragile to modify, or skilled resources are not available to improve functionality.
How do you tackle the adoption of your legacy application data, logic and functionality?
How do you develop a strategic roadmap for deprecation and replacement?
For a purchased or third-party application your options to replace the system are generally limited to an entirely new product and the expensive and complex transition process associated with this. The choices are more limited. For an in-house application the solution can be more flexible, incremental and planned.
No two organizational applications are the same. The process of analysis of any application is the same regardless. Systems accept data input and provide data output. The workflow to construct a data pipeline that encompasses the business logic and intellectual property of the organization for each input/output is the complex analysis set. What is visible to the end consumer, or to an administrative interface is often only a common path of data management. Only detailed documentation and code analysis enables you to identify all of the possible paths of data with specific business logic. This forensic analysis is more specific step for each particular application however the process can be repeated across applications.
With an existing legacy application that includes data, logic and functionality, the approach to incorporate and replace will vary depending on business priorities. Here are two very different approaches to a starting point depending on strategic priorities.
A business wants to personalize the products displayed to a user on their e-commerce site. What is needed is access to the data. Providing a means to migrate data (in near real time) to a different data source is needed. Providing a read-only interface to a subset of data does not require understanding of, modifying or adopting application logic.
A business wants to offer a mobile application to purchase products available on their e-commerce site. Duplicating the website functionality in a mobile application to list and order products is a recipe for an inconsistent consumer experience and the duplication of development and maintenance resources. What is needed is a common API that the website and mobile application can consume to ensure there is one path of business logic to various workflows. This requires at minimum a refactoring of existing business functionality to enable different means of consumption. This does not modify the logic or data. There is often the temptation to re-write the logic at the same time, for example in a newer language, however this introduces multiple critical path factors. Planning the creation of an API is a very strategic approach to extending an existing system. After successful implementation using existing logic there can be a planned and successful refactoring overtime using newer technologies and no critical path dependencies.
The art of dissecting an existing application is knowing how to replace the workflow while maintaining the core functionality and providing tangible benefits of undertaking the work. In general, no organizations have double the number of resources to independently maintain an existing system and a team to develop a replacement system concurrently. An example of improving an existing application by choosing a component replacement process is:
You have an e-commerce site that processes credit card payments. Moving the payment processing from a synchronous operation; i.e. you make a request to a payment processor and you wait for a response to proceed; to an asynchronous operation means this can component can scale because this new design can incorporate queueing and throttling. In the workflow of an order, an existing system is still used to place an order. A new service is created to process placed order and determine if payment is accepted or rejected. The existing application is used for fulfillment of accepted orders. This provides several additional benefits. You improve the customer experience in waiting during the ordering process. You reduce the impact of a failure point in the lifecycle of the customer experience. You provide a gated step that can be independently scaled to avoid any critical stress for system overloading. In addition, the ability to add redundancy via means of an alternative payment gateway when your primary gateway is unavailable resolves an import single point of failure (SPOF). When your business relies on a service provider to conduct important aspects of your business and the only means to know of outages is to see complains on social media, you should be proactive in your business resilience independently of a third party.
Other observed examples of replacing legacy systems functionality include:
- The look verses book capacity of online travel, hotel reservations and events management. By utilizing different technology stacks for the look functionality that needs to scale more significantly, you can reduce loss of service, and still utilize a proven means of processing actual orders.
- The process of consolidating email communication that is spread throughout an application and integrate with a service provider. By removing in-house and at times specific hard-coded response, you can leverage tools that enable staff to customize response for consumer, create additional communication campaigns and track usage by consumers.
- Separating content creation from application development. When tools are used to enabled staff to manage text on a website rather than a developer needing to program a change and rely on the release management process, you enable software developers to focus on functionality rather than text changes.
These examples demonstrate the concepts to tackle reducing a large application by replacing smaller pieces of functionality with a strategic plan. As with many cliches about eating elephants and climbing mountains, there has to be a focus on the end goal, while achieving the goal with small manageable steps.