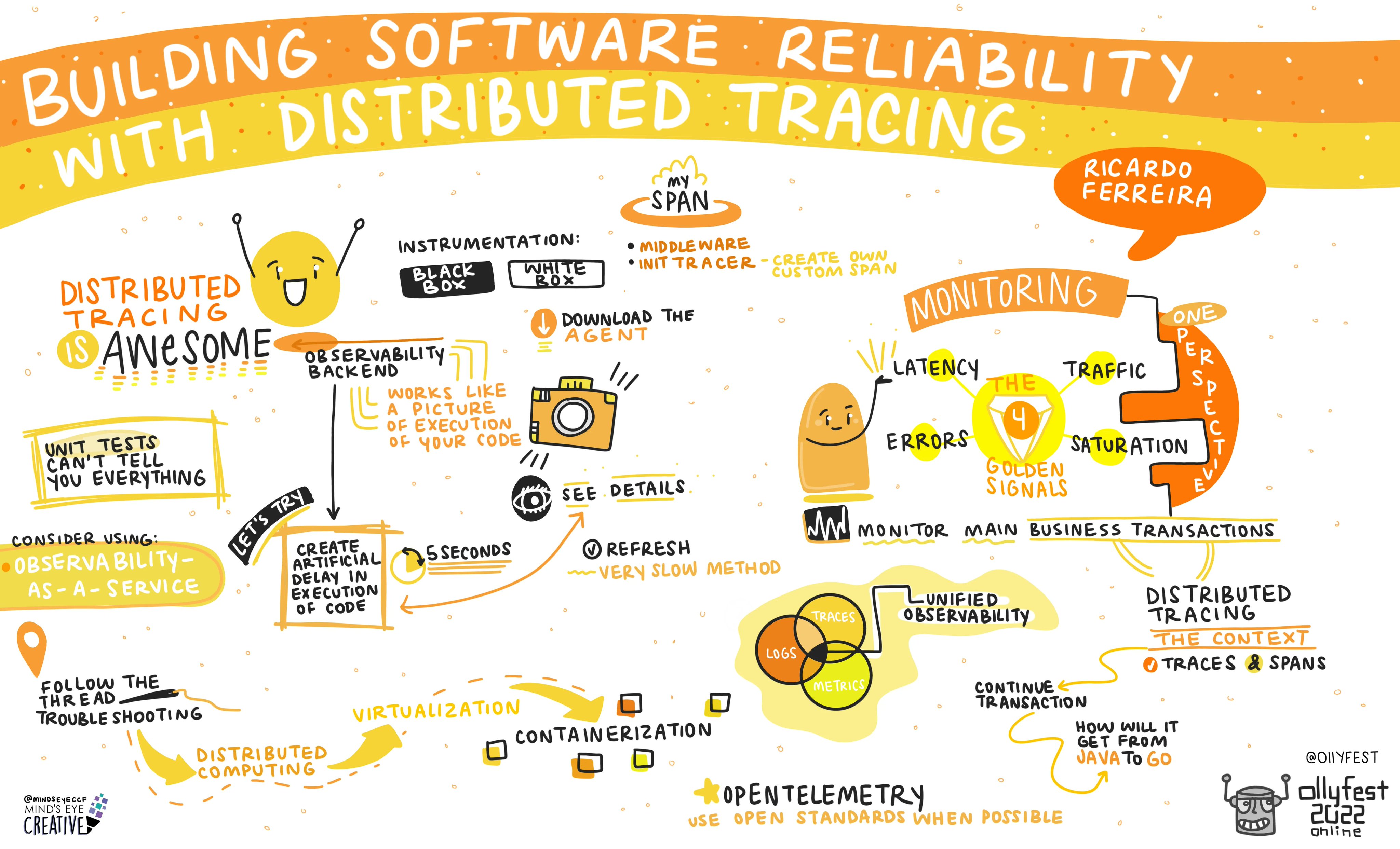
Observability (o11y) is a critical pre-requisite component in software architecture when advocating for and preparing organizations for making informed decisions on the success of their application. Open Telemetry from the Cloud Native Computing Foundation is the goto standard regardless of your choices of monitoring tools. However, observability is just a building block that I need to explain when advocating for having reliable and dependable systems. Observability will not inform you “Was the customer actually impacted, or how many, or how long?”. Observability will not tell you “the root cause of a problem?”.
My five layers of building blocks for Reliability are:
- Observability – The collection of telemetry (metrics, traces and logs) should just be there. If you are using Kubernetes (k8s) and a Java/Python/Node.js application it is already built in. Just do it.
- Reproducibility – The ability with a known set of steps and a given configuration and setup you can reproduce an outcome showing the same observed results is a necessary pre-requisite for any feature development or bug fixes.
- Testability – After being able to consistently reproduce an observed event with measurable results, the running of various experiments using a variety of changes enables you to adequately test future improvements or corrections to the initial situation, whether it’s a known bug, or a new piece of functionality. Reproducible and consistent testing is an essential component to the release of software for a reliable application.
- Scalability – It is impossible to adequately test a system to failure without an observable, reproducible, and testable framework. Many organizations suffer from the management “Can we support X operations” syndrome, when instead the application should know what “X” is automatically, and have adequate safeguards in place to prevent its occurrence. The ability to proactively disable [expensive] features for the good of the entire system is not a common practice for software (aka a dark mode). In fact, many organizations do not even have the capability of customer-level and individual component-level feature flags or related rate limits that can manually be implemented.
- Dependability – A reliable, highly available, and dependable application requires all of the prior layers to be in place to give a level of assurance to your customers and your company that your product is dependable.