As I reflect on this week of my technology journey with the conversations I had, what I learned, and what I wanted to do and write about, I decided what better way to work on multiple blog posts than write about what I’d like to write about.
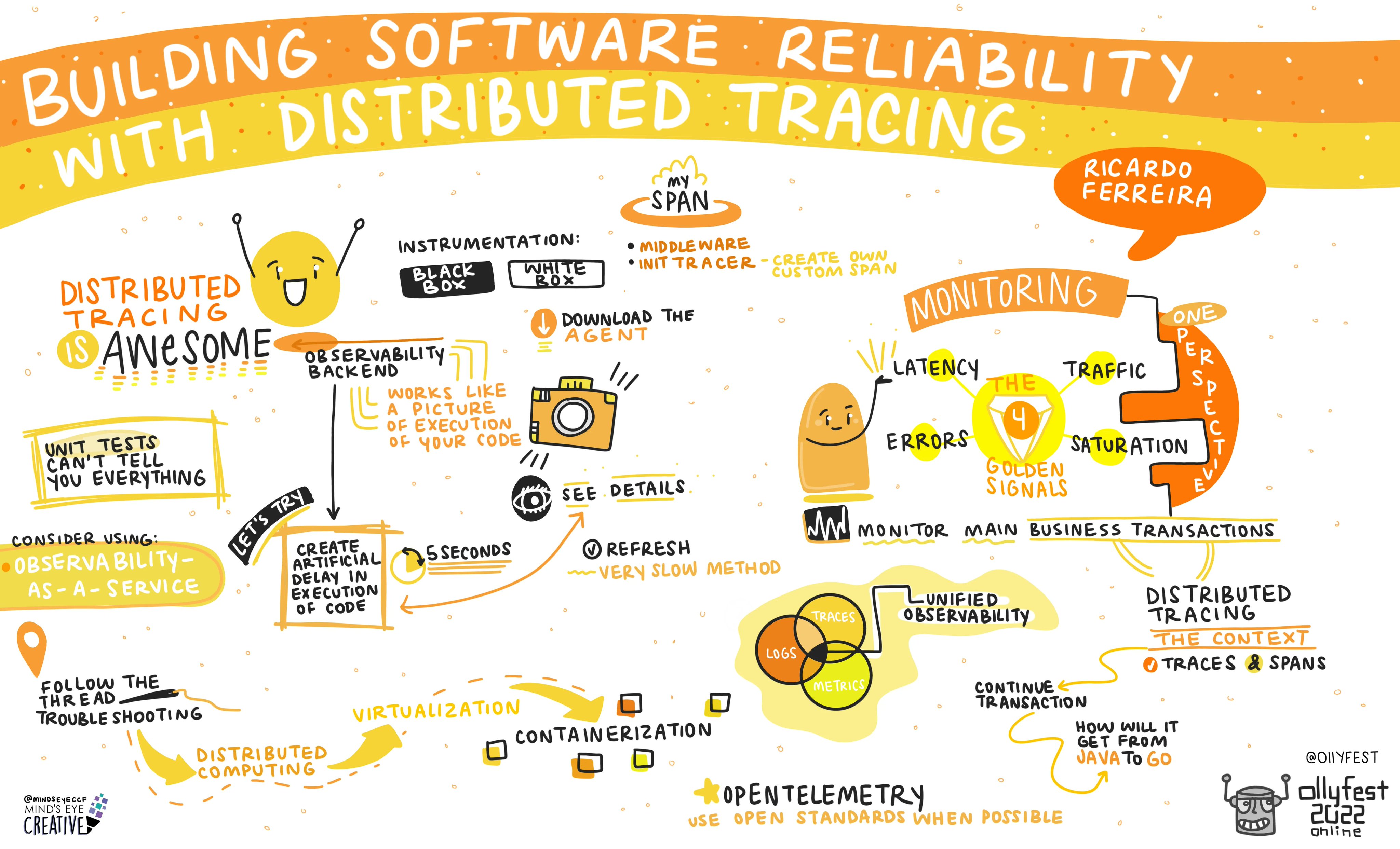
The 2022 observability conference https://o11yfest.org/ is a wrap. For those that are interested in OpenTelemetry this event had plenty of great content with videos with transcripts will become available. Thanks Paul Bruce for your organizing work. While I could only attend some sessions “Building Software Reliability with Distributed Tracing” by Ricardo Ferreira and “Bad Observability” by Stephen Townshend are definitely on my rewatch list. I heard about new things such as keptn – Cloud-native application life-cycle orchestration, and cloudevents – A specification for describing event data in a common way.
A big shot out to Ashton Rodenhiser of Mind’s Eye Creative , who did these amazing animated canvasas during the presentations, I’ve included one at the bottom of this post.
I have never been that into podcasts. I guess I have always been more of a reader than a listener, but this week while having to do some driving, I dove into listing and realized again why I like to read more. Several times I wish I could stop and take notes however lucky for me I was able to see that Thoughworks Technology Podcasts have online transcripts. Coding lessons from the pandemic , The big five tech trends for 2022 and Following an unusual career path: from dev to CEO were all valuable listening. The single best snippet was on rethinking estimation or “no estimate techniques”. I hope I can discuss and implement myself, the “is basically just three things. It’s just right, it’s too big, or it’s insane”.
I took an intro into Web 3.0 with this F5 webinar What is Web3 and How to Build a Dapp? . Yep, I still don’t get Web 3.0 fully, but I can now launch my own blockchain solution with Scaffold-ETH , write Solidity by Example and Learn how to build on Ethereum; the superpowers and the gotchas should I want to in the future.
While I have my favorite YouTube channels that intersect topics including Math, Physics, Engineering, Technology, Facts and Figures, and woodworking (such as Veritasium (11.9M) , CGP Grey (5.35M) , DIYMontreal (151K) and 3×3 Custom (620K) , as part of having random conversations in the social networking of https://o11yfest.org/ I’ve added two new ones to my list of never having enough time. Fireship (1.31M) , and TechLinked (1.73M) .
So what did I learn on YouTube this week in addition to you can make a video of a topic in 100 seconds. VS Code Top-Ten Pro Tips . I know Microsoft’s Visual Studio Code is more popular, I see it in presentations, but I never knew it has become the goto integrated platform. While I default to the good old CLI for vi, git and the like, and Atom , this video highlighted I need to use VS Code. We all know computer and math gives undesired results Why do computers suck at math? was fun to watch. And I’ve ordered the plans and getting supplies to make this 6-in-1 Trim Router Jig .
I’ll leave this blog with a few images reflecting the week.
- A picture can tell a story of your presentation – Building Software Reliability with distributed Tracing
- It should be your job! – It’s not my job
- Synthetic datasets are not the real deal – Test Data and Training Data
- What is your data quality? – AI is only as good as your input data
- If you want to get the truth, you really have to dig deeper, what is on the surface is not the whole story. Boy I like the iceberg analogy for so many things, but I never knew Easter Island heads were just 1/4 of the whole body . Wow!