Blog
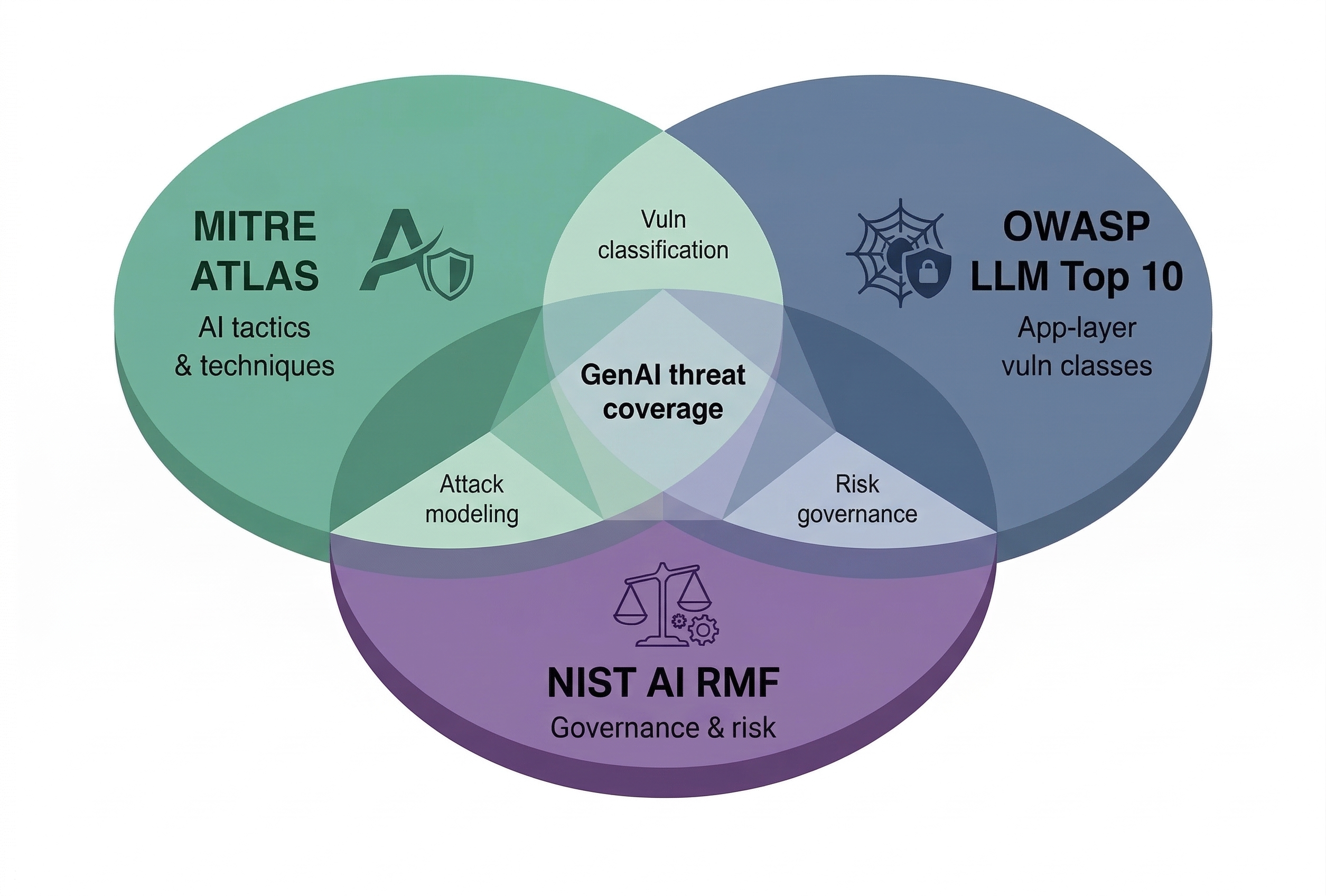
Foundational Frameworks for GenAI Security Analysis
Three frameworks form the analytical foundation of this series’ threat analysis, selected for their complementary coverage of the GenAI security landscape and their broad adoption across enterprise security practices. The MITRE Adversarial Threat Landscape for AI Systems (MITRE ATLAS) maps tactics and techniques specific to AI systems.
Read more
A first look at MySQL 26.7 Early Access
MySQL has dropped its newest release , categorized as “Early Access” and available at https://labs.mysql.com/ . While this post is not going to go into depth, I wanted to at least validate the management changes you verify between normal MySQL upgrades.
Read more
Where is the technology breakdown? Can AI help?
On a major financial institution website I was asked to complete a contact form. This organization has millions of existing customers. This is not a startup, yet the quality of work is something a junior developer would fail at an interview if they provided the answer.
Read more
Why My Mac Was Not Using Post-Quantum SSH With GitHub (And How I Fixed It)
In my previous post I made the case that the only post-quantum protection that counts is the algorithm your connection actually negotiates. This post is what happened when I checked my own laptop.
Read more
Q Day Is Coming: A Plain-English Guide to Post-Quantum Cryptography
Every time you see the padlock in your browser, push code over SSH, or your application connects to a database, TLS or SSH is quietly doing two jobs. First, it proves you are talking to the real server and not an impostor.
Read more
VillageSQL Extensions with versioning
VillageSQL has just released it’s latest version 0.0.5 , describing this as stable release for installations with full MySQL 8.4.10 compatibility. With my primary work around extensions, specifically vsql-statistics , I took the new versioning features for a test.
Read more
Producing IQR and Outlier statistics with SQL
The interquartile range (IQR) measures the spread of the middle 50% of a distribution — the distance between the first quartile (Q1) and the third quartile (Q3). Combined with Tukey’s 1.
Read more
Producing Mode statistics with SQL
The mode is the value or values that appear most frequently in a dataset. Unlike the mean or median, it applies naturally to categorical and ordinal data — star ratings, product codes, survey responses — and reveals what is most common, not what is average.
Read more
Extending MySQL Capabilies with UDFs, Plugins and Components - Part 2
MySQL offers three different approaches to extending the SQL capabilities with the default product you download and install. These are: User Defined Function (UDF) MySQL Manual MySQL Plugin MySQL Manual MySQL Component MySQL Manual In my prior post I provided a new uuidv function that accepted a numeric argument to return a string of the version of UUID specified.
Read more
Producing Alternative Means statistics with SQL
MySQL’s built-in AVG() computes the arithmetic mean — the sum divided by the count. That is the right default for many questions, but it is not always the right measure of central tendency.
Read moreExtending MySQL Capabilities with UDFs, Plugins and Components
MySQL offers three different approaches to extending the SQL capabilities with the default product you download and install. These are: User Defined Function (UDF) MySQL Manual MySQL Plugin MySQL Manual MySQL Component MySQL Manual For the purposes of this post I will be using the current LTS version MySQL 8.
Read more
Producing One-Sample Z-Test statistics with SQL
The one-sample Z-test determines whether a sample mean differs significantly from a known population mean when the population standard deviation is also known. It is the appropriate test when the population parameters are established — quality control benchmarks, national averages, long-run process measurements — and you want to evaluate whether a new sample is consistent with them.
Read more
Switching to JSON Error Logging in MySQL
You no longer need to manually parse the MySQL Error log via scripting and RegEx pattern matching. Using the component_log_sink_json component you can obtain JSON error logging for easier parsing.
Read more
Installing MySQL 9.7 LTS Community Edition on CentOS
Historically installing MySQL on a RedHat Compatible Linux server was as simple as yum install mysql-server. Today’s MySQL Oracle Linux, Red Hat Enterprise Linux, CentOS, and Fedora 9.7 instructions are not accurate mixing in 8.
Read more