Blog

Improving your MySQL Security Posture Presentation
At the MySQL BR Conference 2025 I had the opportunity to speak about Improving Your MySQL Security Posture. You can find a copy of my slides on my Presentations , and a Portugese (Brazil) translation.
Read more
MySQL and Heatwave Summit Presentation
Last week I had the opportunity to speak at the MySQL and Heatwave Summit in San Francisco. I discussed the impact of the new MySQL 8.0 default caching_sha2_password authentication, replacing the mysql_native_password authentication that was the default for approximately 20 of the 30 years that MySQL has existed.
Read more
Readyset QueryPilot Announcement
At the MySQL and Heatwave Summit 2025 today, Readyset announced a new data systems architecture pattern named Readyset QueryPilot . This architecture which can front a MySQL or PostgreSQL database infrastructure, combines the enterprise-grade ProxySQL and Readyset caching with intelligent query monitoring and routing to help support applications scale and produce more predictable results with varied workloads.
Read more
More CPUs or Newer CPUs
In a CPU-bound database workload, regardless of price, would you scale-up or scale-new? What if price was the driving factor, would you scale-up or scale-new? I am using as a baseline the first available AWS Graviton2 processor for RDS (r6g).
Read more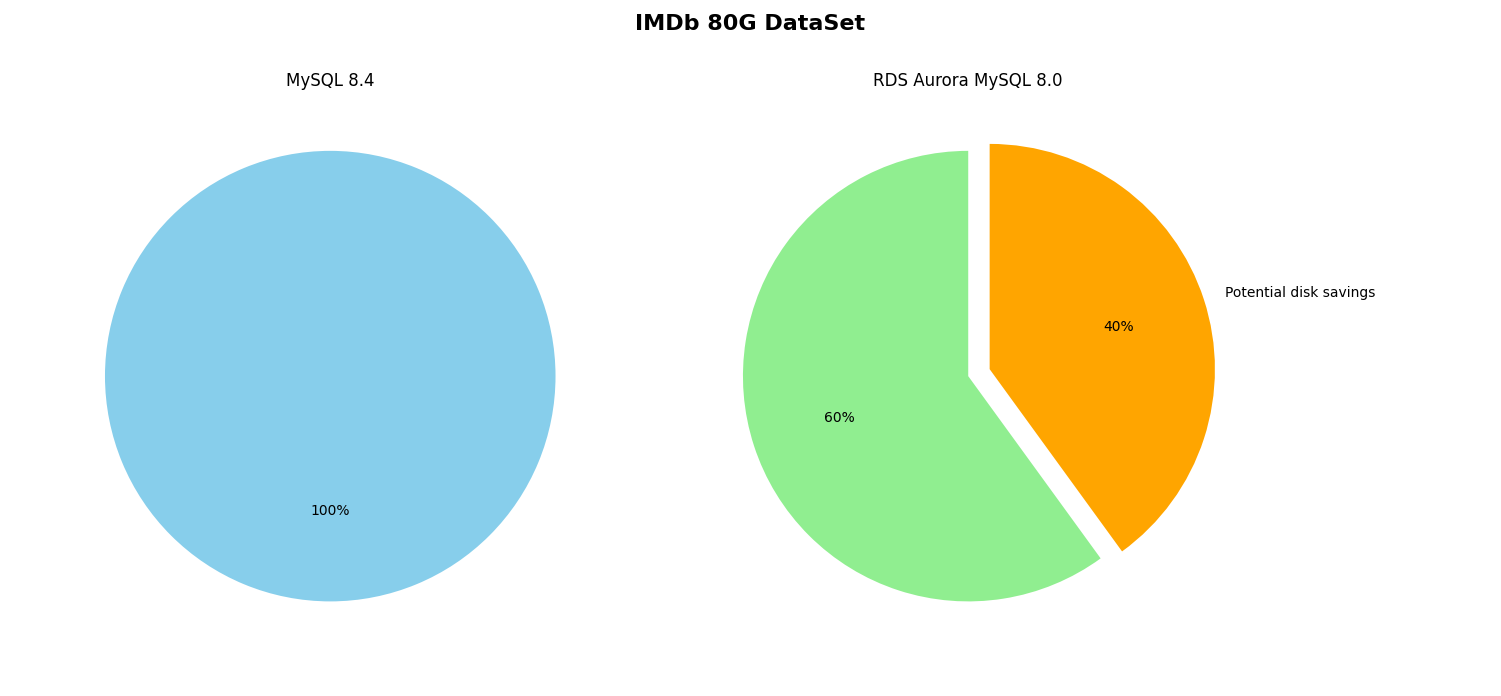
An Interesting Artifact with AWS RDS Aurora Storage
As part of using public datasets with my own Benchmarking Suite I wanted upsize a dataset for larger volume testing. I have always used the INFORMATION_SCHEMA.TABLES data_length and index_length columns as a sufficiently accurate measurement for actual disk space used.
Read more
How long does it take the ReadySet cache to warm up?
During my setup of benchmarking I run a quick test-sysbench script to ensure my configuration is right before running an hour+ duration test. When pointing to a Readyset cache where I have cached the 5 queries used in the sysbench test, but I have not run any execution of the SQL, throughput went up 10x in 5 seconds.
Read more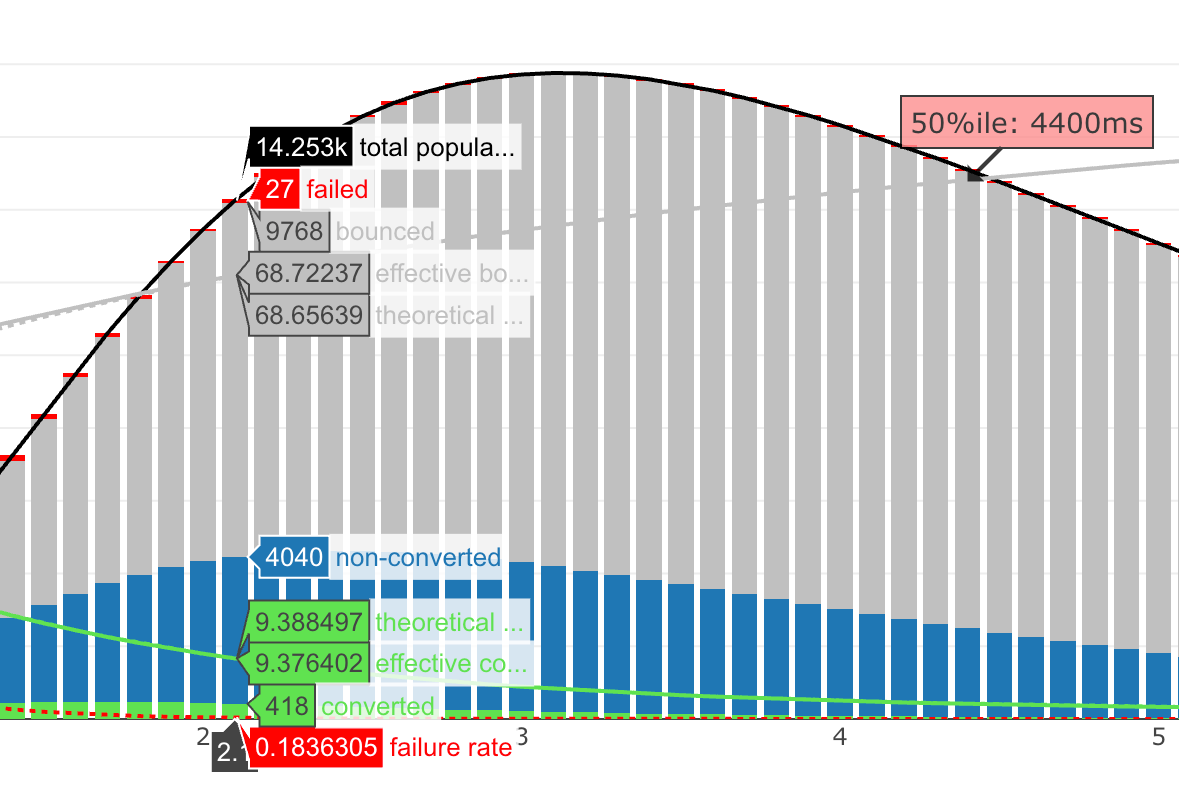
Monitoring Latency with Throughput
Higher throughput does not imply improved performance. This is a common problem when the need for an application to support more users, you provide higher concurrency and that appears to show the capability to support higher throughput.
Read more
Using Readyset Caching with AWS RDS MySQL
Readyset is a next-generation database caching solution that offers a drop-in; no application code changes; approach to improve database performance. If you are using a legacy application where it is difficult to modify SQL statements, or the database is overloaded due to poorly-designed SQL access patterns, implementing a cache is a common design strategy for addressing database reliability and scalability issues.
Read more
Sysbench Under the Covers
Sysbench is a popular open-source benchmarking tool designed to evaluate the performance of system components such as CPU, memory, disk I/O, and databases. It is commonly used for testing MySQL, PostgreSQL, and other databases under different load conditions.
Read more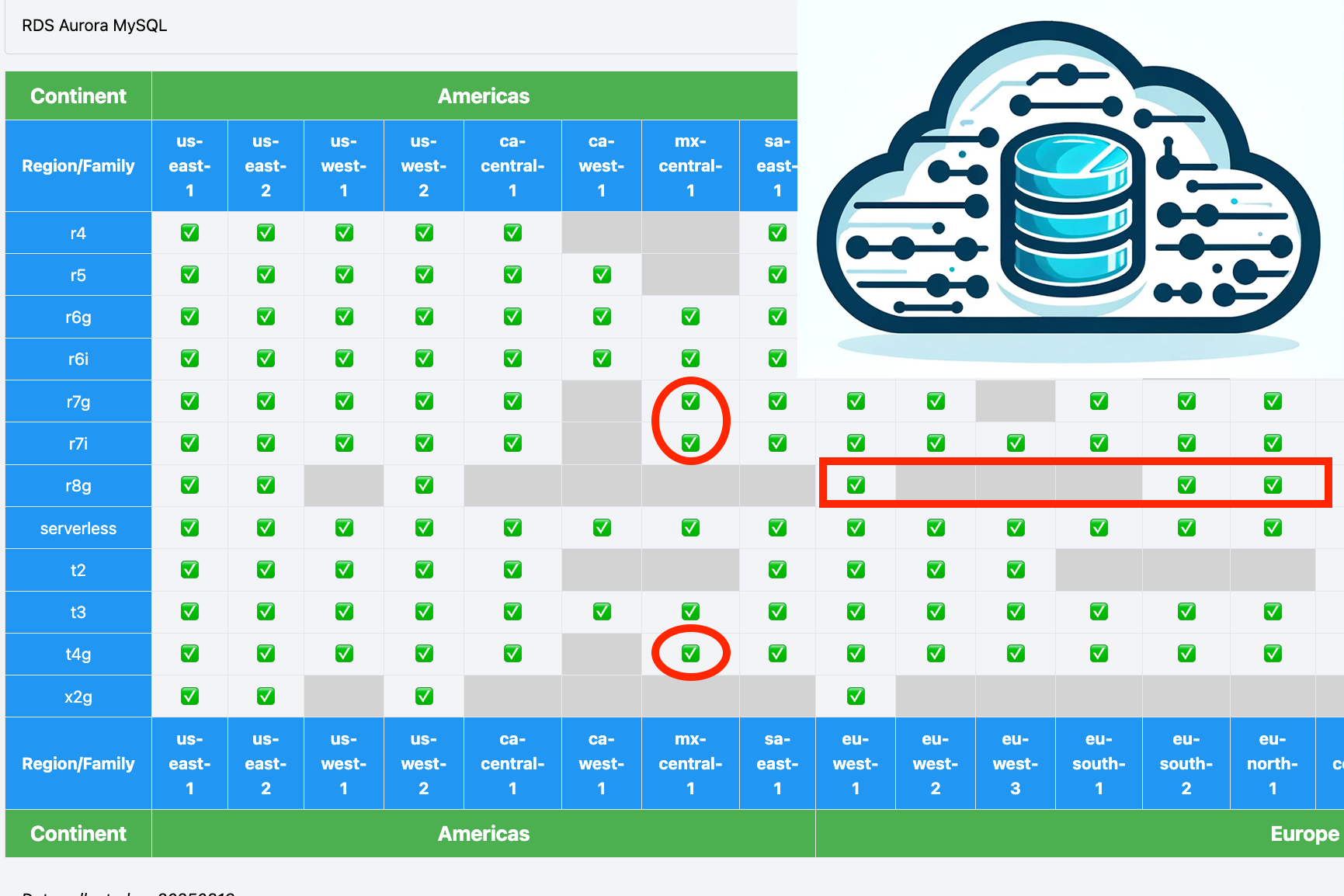
Tracking new AWS Database Infrastructure Availability
AWS can drop 10+ articles a day just in the What’s New feed. You either need an eagle eye, or luck to keep up if you run multiple AWS database products across multiple regions and managing infrastructure.
Read more
Evaluating Readyset Caching for MySQL
Readyset is a database caching solution for MySQL and PostgreSQL . For applications that have increased load on your primary database, or use scale-out infrastructure to support a high-read workload, ReadySet can be a drop-in solution to address current performance issues.
Read more
Creating a More Realistic Benchmark
Common benchmark approaches fall into two general categories, synthetic testing and realistic testing. You have the most generic operations from a synthetic test, starting with the most simple example using a single table, a single column, and for a single DML operation.
Read more
Testing, Benchmarking, Evaluating
Testing and benchmarking are widely used terms in software technology, each serving a distinct purpose and goal. With the increasing adoption of AI in software development, the term evaluating has become significant and with this the re-emergence of what is quality assurance.
Read more
Your Attack Vector Extends Beyond Production Systems
A common data security issue is the unprotected copying of production data to non-production environments without any redaction, masking, or filtering. This practice poses a serious risk. A malicious actor will target the weakest link in your infrastructure, including non-production accounts and the developer systems accessing them.
Read more