This week I wanted to share more about Observability and the CNCF foundation project Open Telemetry . Observability is a necessary foundation for any information system however observability does not answer questions that are essential for a successful business to operate. Let me explain in more detail.
Observability on it’s own does not answer these questions:
- Was the customer impacted due to an event?
- What is the root cause of a customer impacted situation?
So, no matter how much data one can provide here, what is the data story you need to be telling?
Let me give you a concrete example of a recent actual outage example. Your cloud provider has an outage at one data center within one availability zone in one region. Your observability shows that 13% of your fleet’s infrastructure is impacted. You employ a multi-AZ single region primary customer-facing website. While there are alarms and alerts and pages, your infrastructure balances the load, IaC relaunches the necessary replacements and most systems return to an apparent steady-state (I’ll leave the “hint” of apparent for another time).
Was the customer experience actually impacted? There are alerts of an increase in 500 errors, however, this quickly resolves. There are some small increases in latency of primary functions that you have on your dashboard? What did the customer actually experience? Was it just a few customers, all of your customers, or certain customers based on what level of functionality they were performing, for example searching for products to purchase, adding products to a shopping cart, or checking out?
Observability is not going to answer the fundamental question of “Was the customer impacted?”. Your business needs to define the metrics of measurement and actually capture this. Is a single customer of 100,000 active customers receiving a few 500 errors considered impact? Is 1% of served traffic affected considered impact? What duration? What is actually necessary are business-specific metrics around your customer sentiment. Is it simply a measurement of revenue per minute compared with seasonal measurements of the same time of day, the same day of the week, and with the same impactful event such as a public holiday. Is it more complicated? No amount of RTO, RPO, MTTD, MTTR, multi-AZ, or DR resiliency is going to help you here.
Let’s take the same situation, but this time the IaC doesn’t work. More alarms are going off, and certain layers of your infrastructure are highly saturated. Manual attempts to correct the loss of resources do not work? Where is the root cause of the problem? How can you fix the root cause? What if the root cause is a portion of your infrastructure that is a purchased product by another provider, and is a technology stack that does not match your own companies or the skills of your employees? How do you address this “house is on fire” situation?
In the above example, AWS suffered 3 outages last December 2021 and one was the loss of power to a single us-east-1 availability zone. If you did not know this, us-east-1a for your account does not mean us-east-1a for a different customer of AWS. In fact, it doesn’t even mean the same if you have multiple different accounts per environment. An availability zone is also not one data center. Prior incidents have shown that it could be a small percentage. One AWS AZ could comprise 5-10-15+ different data centers.
Also, in the above example, if your container registry is highly-available, but an incorrectly configured third-party product and is now in a state where you cannot re-launch any infrastructure because the necessary images are inaccessible, your business is hobbled. Have you planned for this situation before? Let me share some more hypothetical questions about this scenario. The stack is not what your on-call resources know, there is insufficient documentation about this system, and there is no test infrastructure in order to reproduce the issue, or validate any hypothesis. What if there is no support agreement with the company that sold the product?
As you can see the role of an architect, whether a solutions architect, a data architect, an enterprise architect or the principal architect, you could consider in many organizations this far exceeds the likely scope of your day-to-day obligations. Is there such a thing as a disaster-preparedness architect, or a chaos architect? Is the architect not even a sufficiently leveled responsibility here! Is it the Head of, or the Director of need in your business? Is there such a thing as a Chief Reliability Officer (CRO)? Seems a google search finds results. Added to my reading todo list.
My professional experience is that Observability is the first essential layer of total observability infrastructure for your organization. The full stack actually includes:
- Observability
- Reproducibility
- Testability
- Scalability
- Reliability
All of these layers are essential. Each layer is a prerequisite for the next. In your position in the organization where do you start? As a reliability resource you need Observability first. As a test engineer, you actually cannot start with Testability. As a C-suite executive, you need to know that system Reliability comes first, but how to you validate that?
I will be providing a much more in depth paper on this in the future.
What is also missing from this list is one essential business-wide requirement — Ownership. If in the entire organization, from the developer to the manager, to the customer support representative to the c-suite officer, every level is needed to take joint ownership in customer success. The weakest link is the actual problem and no amount of instrumentation, process or dashboards can address that.
Moving on, VS Code again came up in conversation in my tech circles, I really should practice using it.
My neighbor purchased the company Steel Bee
– Long live your razors. It was a fascinating conversation about not creating a new product, but selecting an existing product that has a drop-ship infrastructure already in place and an Amazon and Shopify store presence. How do you measure the success of something you did not build? How can you improve on it?
On a personal note, I am about to venture into the world of CNC routing. Anybody with tips & tricks and open-source software to use? I am currently trying Carbide Create
With all that is happening locally, let us not forget to #StandWithUkraine .
This week in images.
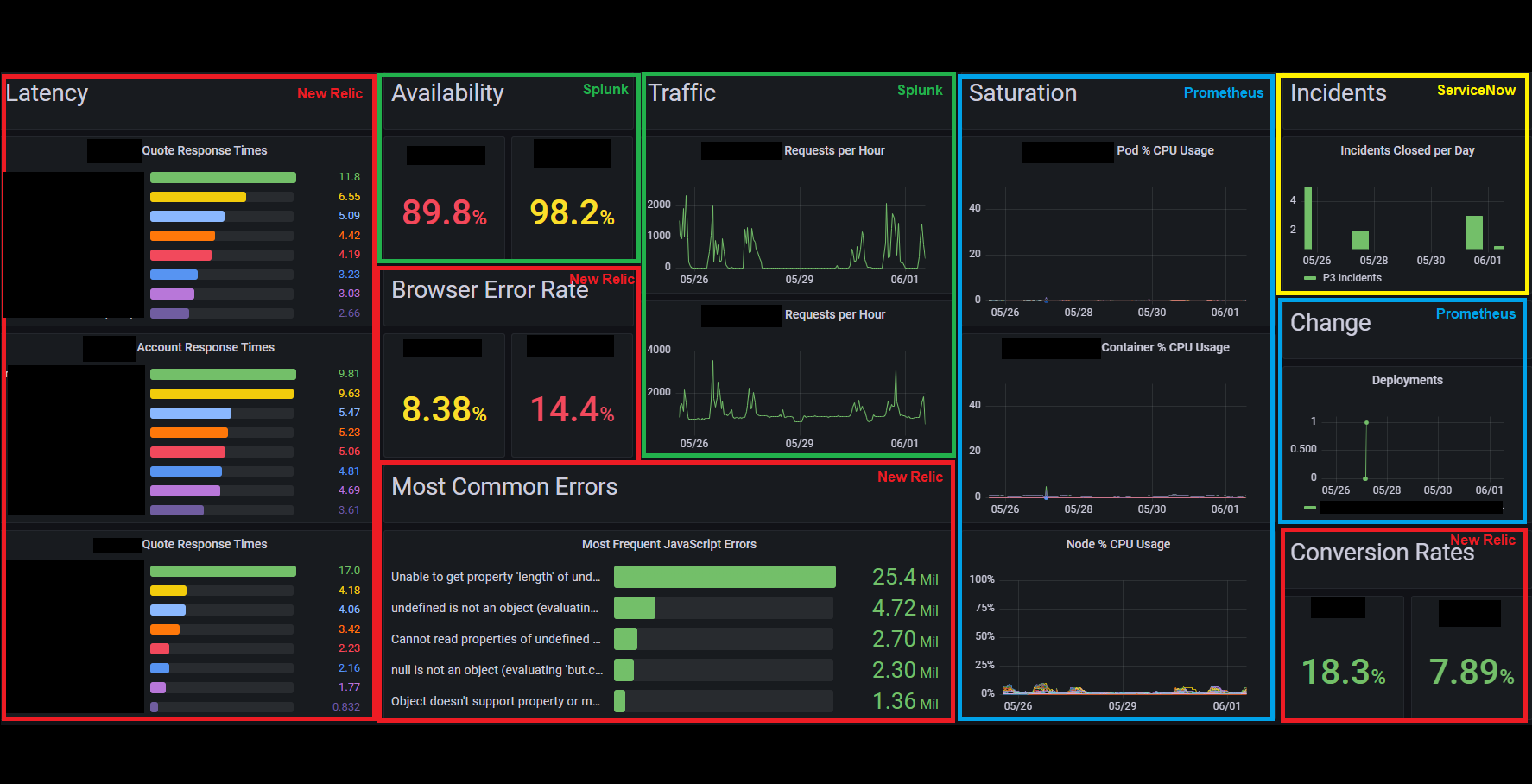
- A Grafana dashboard of 3 different products that offer different insights. Quite interesting. https://twitter.com/the_kiwi_sre/status/1532517294634856448
- Learn how to draw 100 DevOps inspired drawings https://twitter.com/MindsEyeCCF/status/1533049346178031617
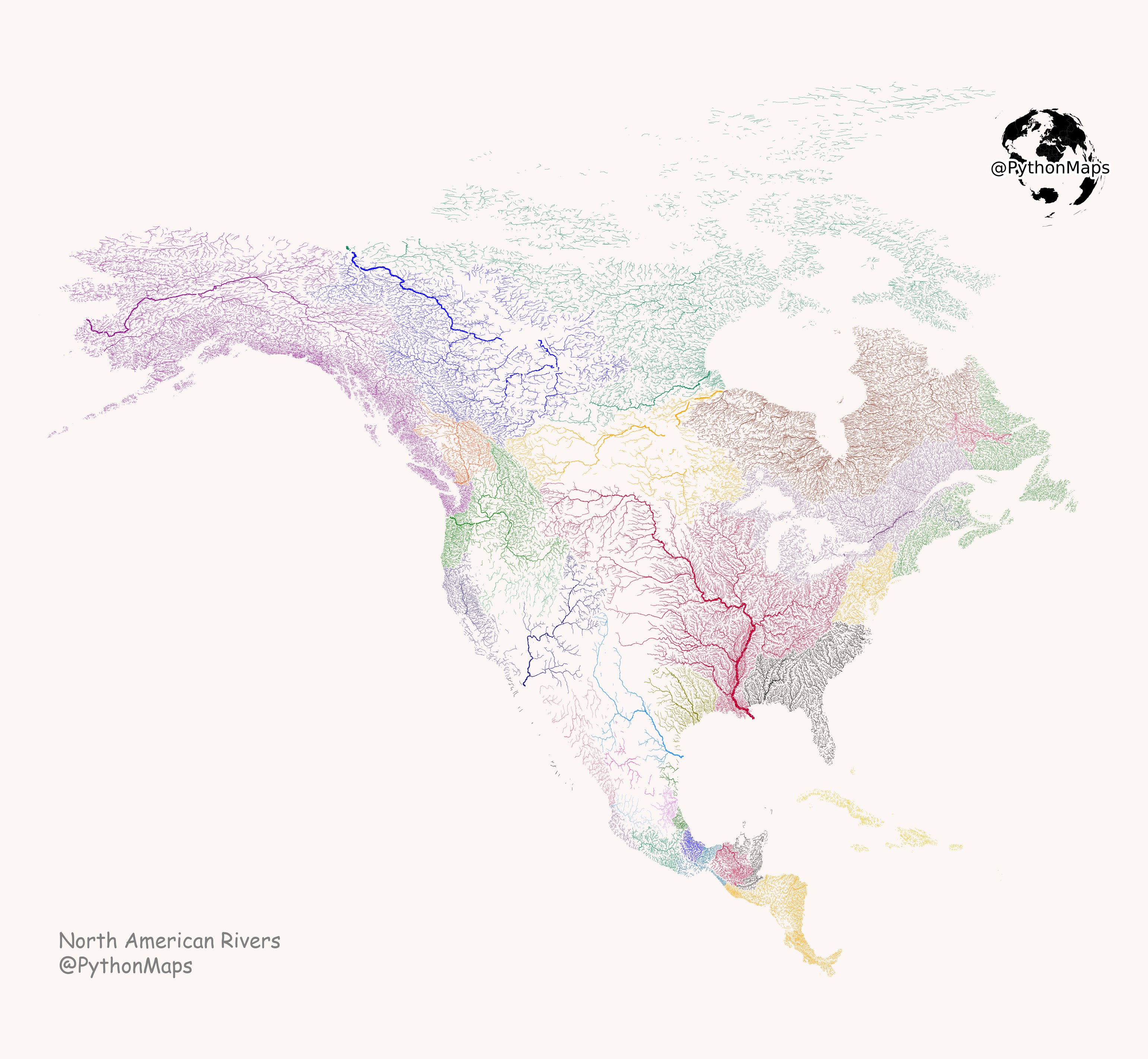
- And the water in North America is where? https://twitter.com/PythonMaps/status/1530224635761106946
- A bird’s Eye view of Defence in depth structure of Cybersecurity https://twitter.com/DemaiTech/status/1533074997710839809
- And the water in North America is where? https://twitter.com/PythonMaps/status/1530224635761106946
- Learn how to draw 100 DevOps inspired drawings https://twitter.com/MindsEyeCCF/status/1533049346178031617