
Readyset is a next-generation database caching solution that offers a drop-in; no application code changes; approach to improve database performance. If you are using a legacy application where it is difficult to modify SQL statements, or the database is overloaded due to poorly-designed SQL access patterns, implementing a cache is a common design strategy for addressing database reliability and scalability issues.
In this series of benchmark posts, I will be demonstrating the improvement in query performance (i.e. latency), as well as the increased query throughput for your application when adding a Readyset cache with your MySQL database. This solution does not require you to modify your existing application code to reap the benefit from caching queries. A Readyset cache also reduces the resource utilization on your database performing the original SQL queries.
Benchmark 1 Highlights
- Comparing a RDS database (8 vCPUs) under peak load adding a Readyset cache (4 vCPUs).
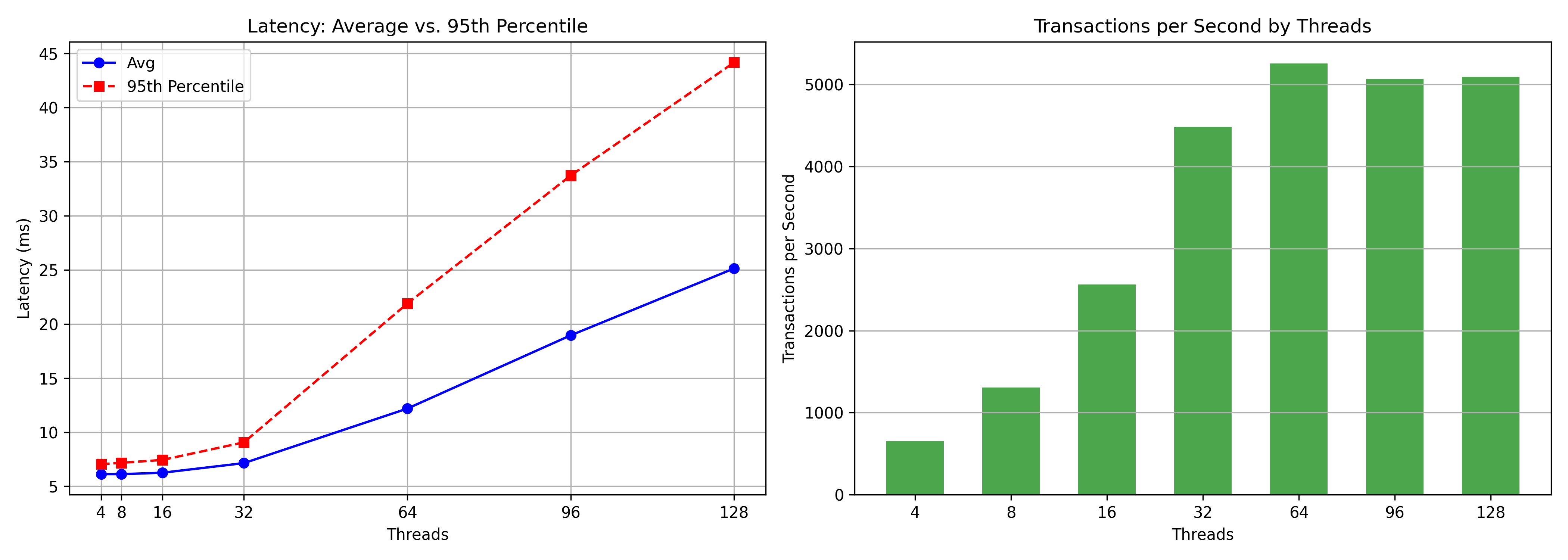
- RDS transactions (5 SELECTs per transaction) peaked at 5.2k per second using 64 threads.
- Readyset transactions peaked at 17.2k per second using 16 threads. (3x throughput improvement).
- The average RDS transaction response was 12.2ms, and the 95th percentile was 21.9ms.
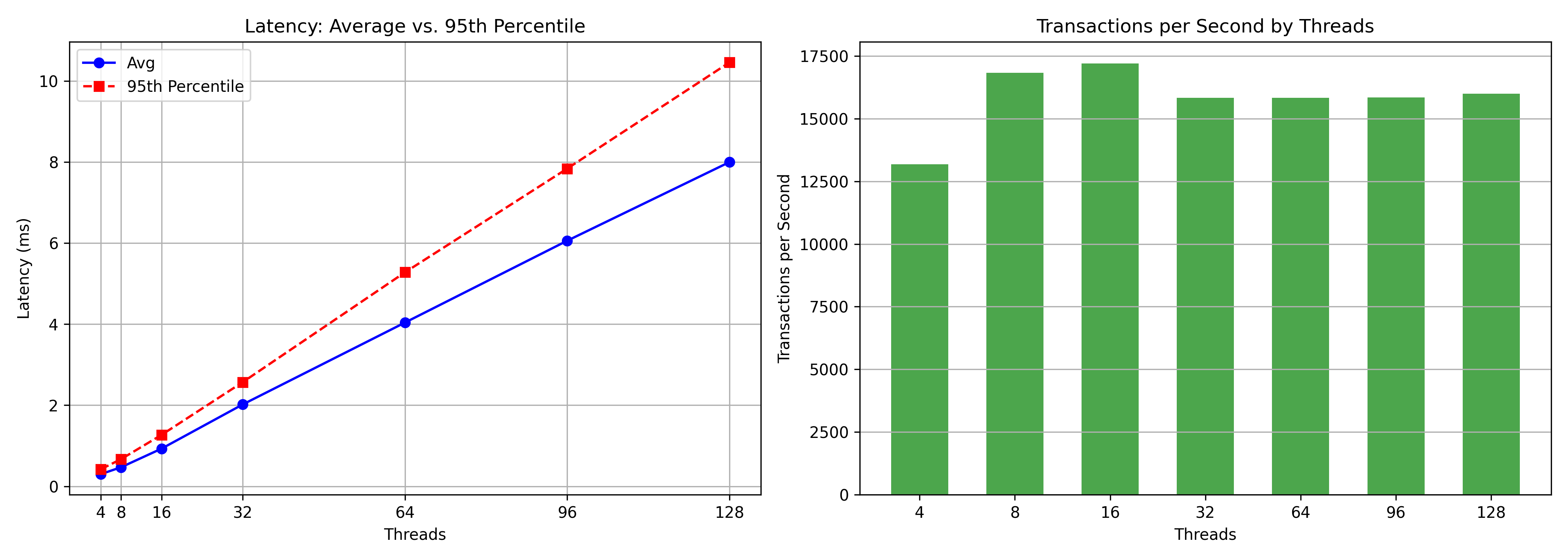
- The average Readyset transaction response was 0.93ms (13x faster), and 95th percentile was 1.3ms (17x faster).
Instance Types Used
The RDS database instance type used has 8 vCPUs and was selected to support a larger number of database threads in a typical simulated production workload. In subsequent tests I will be using larger instance types.
| Server Purpose | Instance Type Used | Resource Specs | Price Per Hour (us-east) |
|---|---|---|---|
| Database | db.r6g.2xlarge | 8 vCPUs, 64GB RAM | $0.86 (MySQL) ($0.90 PostgresSQL) |
| Cache | r6i.xlarge | 4 vCPUs, 32GB RAM | $0.25 |
Goal: This benchmark is not an apples-to-apples comparison. I am not comparing a 8 vCPU Readyset cache with a 8 vCPU RDS database. I do intend to show a more direct comparisons with future posts.
Comparing a 8 vCPU Readyset cache with a 8 vCPU RDS database produces exceptional responses and are included in my published benchmark results.
With 16 threads, an 8 vCPU Readyset cache produced 19.5k transactions (3.75x improvement) at a faster response of 0.82ms (15x faster). The Readyset cache also peaked at 23.3k transaction per second (4.5x throughput improvement) with higher thread concurrency and with an response time still better than RDS.
In this benchmark I am emulating a real-world situation that demonstrates the benefit of adding a caching solution to an existing application infrastructure to address several pressure points including performance and cost. For a situation involving the need to upgrade from an r6g.4xlarge ($1,278 pre month) primary instance to an r6g.8xlarge ($2,551 per month) primary instance and HA replica, the introduction of Readyset can provide multiple benefits for consideration.
RDS Throughput and Latency
Readyset Throughput and Latency
How do you Measure Overall Improvement?
There is no standard method to combine two of the most important benchmark measurements; the improved throughput and reduced latency; to provide a single percentage improvement.
The Weighted Geometric Mean provides one configurable calculation where you can place different weights on individual measurement. If both throughput and latency are given equal weighting the result in this first benchmark test is a 552% improvement implementing a Readyset cache.
There are other approaches that could be considered for calculating a single number % improvement. The Inverse Latency, the Harmonic Mean, and the Normalized Performance Score are other examples..
Any detailed assessment when evaluating a revised product strategy would include multiple benchmarks, and results combined with different factors including cost savings, time to implement and complexity to implement, As shown in later graphs a situation providing maximum throughput may not meet ideal latency goals.
As a Data Architect, when I consider each data access path for an application, I like to define five (5) primary artifacts per access path.
- What are the data inputs?
- What are the data outputs?
- Throughput distribution at low, normal and peak times.
- Latency expectations at low, normal and peak times
- Freshness/Staleness of results.
The Benchmark
IMDb Movie Titles
While sysbench tests focus on local machine performance, and generally each individual test looks at one specific SQL condition, my approach to benchmarking is to move from a synthetic strategy to a more realistic strategy in several ways.
The IMDb title benchmark is one of several examples using real-life data sources, a well-normalized schema, and sometimes queries that are not the most ideal. Some queries are a little inefficient intentionally to better represent what a typical application would be. For example, we use the title of the movie for queries, while this column is indexed. Subsequent queries also use the title field. A more efficient application may have retrieved the primary key, and used this in subsequent queries optimized to use this primary key, both reducing the large key used, and also potentially dropping an entire table required for some queries.
Very few applications are actually deployed on a single server, and this benchmark includes separation of the application, cache and database to emulate more real world situations.
This benchmark is available for you to reproduce at https://github.com/ronaldbradford/benchmark/ . For more information about the source data see the IMDb DataSet used.
Database Setup
- Using the
r6*family of AWS Instance Types - The entire database (20GB) is held in InnoDB Buffer Pool
- This first benchmark are read only tests
- RDS MySQL Version 8.0.40
- Default RDS parameter groups, plus binary logging enabled and the performance schema enabled
- sysbench version
1.1.0-de18a03compiled from source to support external TLS connections to AWS RDS - Each transaction is 5 SELECT statements
- For this benchmark there is an initial warmup period (600 seconds) and then a warmdown period (120 seconds).
- For each thread count (4,8,16,32,64,96,128), there is an execution period (600 seconds) and then a warmdow period (120 seconds).
Low volume
While the highlights showed the best throughput per test, even at low usage the cache exhibited significantly better performance results.
- At 4 threads, the RDS transaction response was 7ms, Readyset was 0.42ms (17x faster).
- At 4 threads, the RDS throughput was 650 queries, Readyset was 13.1k (20x increase).
- At the 95% percentile for 4 threads, RDS latency was 21ms (a 80% increase), Readyset latency was 1.2ms (a 35% increase).
SQL Statements
The title-5 test case emulates an API call that would populate a webpage about a given movie title of data available from the dataset. This would include a page showing:
- Details about the Movie
- Genres of the Movie
- Rating of the Movie
- Characters in the Movie
- Principal people associated with the Movie
See at the end of the post for information about the SQL statements, example data output, and Query Execution Plans (QEP) of queries.
Be sure to review my next benchmark where I compare different AWS Instance Types using the same workload.
SQL Statements
These are the five SQL statements for this test.
SELECT /* Movie Details */ t.*
FROM title t
WHERE t.title = ?
AND t.type = 'movie';
SELECT t.* FROM title t WHERE t.title = ? AND t.type = 'movie';
SELECT /* Movie Genres */ g.genre
FROM title_genre g
JOIN title t ON g.title_id = t.title_id
WHERE t.title = ?
AND t.type = 'movie';
SELECT /* Movie Ratings */
t.title,
r.average_rating,
r.num_votes
FROM title t
JOIN title_rating r ON t.title_id = r.title_id
WHERE t.title = ?
AND t.type = 'movie';
SELECT /* Movie Characters */
n.name AS name,
tnc.character_name
FROM name n
JOIN title_name_character tnc ON n.name_id = tnc.name_id
JOIN title t ON t.title_id = tnc.title_id
WHERE t.title = ?
AND t.type = 'movie';
SELECT /* Key people in the movie */
n.name,
tp.category
FROM title_principal tp
JOIN title t ON t.title_id = tp.title_id
JOIN name n ON n.name_id = tp.name_id
WHERE t.title = ?
AND t.type = 'movie';
Example Query Output
This is an example of the output using an example movie title.
--------------
SELECT t.* FROM title t WHERE t.title = 'Interstellar' AND t.type = 'movie'
--------------
+----------+-----------+-------+--------------+----------------+----------+------------+----------+---------------+---------------------+
| title_id | tconst | type | title | original_title | is_adult | start_year | end_year | run_time_mins | updated |
+----------+-----------+-------+--------------+----------------+----------+------------+----------+---------------+---------------------+
| 790651 | tt0816692 | movie | Interstellar | Interstellar | 0 | 2014 | NULL | 169 | 2025-03-08 03:14:59 |
+----------+-----------+-------+--------------+----------------+----------+------------+----------+---------------+---------------------+
1 row in set (0.00 sec)
--------------
SELECT g.genre FROM title_genre g JOIN title t ON g.title_id = t.title_id WHERE t.title = 'Interstellar' AND t.type = 'movie'
--------------
+-----------+
| genre |
+-----------+
| Adventure |
| Drama |
| Sci-Fi |
+-----------+
3 rows in set (0.00 sec)
--------------
SELECT t.title, r.average_rating, r.num_votes FROM title t JOIN title_rating r ON t.title_id = r.title_id WHERE t.title = 'Interstellar' AND t.type = 'movie'
--------------
+--------------+----------------+-----------+
| title | average_rating | num_votes |
+--------------+----------------+-----------+
| Interstellar | 8.7 | 2301664 |
+--------------+----------------+-----------+
1 row in set (0.00 sec)
--------------
SELECT n.name AS name, tnc.character_name FROM name n JOIN title_name_character tnc ON n.name_id = tnc.name_id JOIN title t ON t.title_id = tnc.title_id WHERE t.title = 'Interstellar' AND t.type = 'movie'
--------------
+---------------------+------------------+
| name | character_name |
+---------------------+------------------+
| Matthew McConaughey | Cooper |
| Ellen Burstyn | Murph |
| John Lithgow | Donald |
| Anne Hathaway | Brand |
| Francis X. McCarthy | Boots |
| David Oyelowo | School Principal |
| Jessica Chastain | Murph |
| Collette Wolfe | Ms. Hanley |
| Timothée Chalamet | Tom |
| Mackenzie Foy | Murph |
+---------------------+------------------+
10 rows in set (0.00 sec)
--------------
SELECT n.name, tp.category FROM title_principal tp JOIN title t ON t.title_id = tp.title_id JOIN name n ON n.name_id = tp.name_id WHERE t.title = 'Interstellar' AND t.type = 'movie'
--------------
+---------------------+---------------------+
| name | category |
+---------------------+---------------------+
| Matthew McConaughey | actor |
| Ellen Burstyn | actress |
| John Lithgow | actor |
| Hans Zimmer | composer |
| Anne Hathaway | actress |
| Nathan Crowley | production_designer |
| Francis X. McCarthy | actor |
| Christopher Nolan | director |
| Christopher Nolan | writer |
| Christopher Nolan | producer |
| Jonathan Nolan | writer |
| Lynda Obst | producer |
| David Oyelowo | actor |
| John Papsidera | casting_director |
| Lee Smith | editor |
| Emma Thomas | producer |
| Hoyte Van Hoytema | cinematographer |
| Jessica Chastain | actress |
| Collette Wolfe | actress |
| Timothée Chalamet | actor |
| Mackenzie Foy | actress |
+---------------------+---------------------+
21 rows in set (0.00 sec)
Query Execution Plans (QEP)
> EXPLAIN SELECT t.* FROM title t WHERE t.title = 'Interstellar' AND t.type = 'movie';
+----+-------------+-------+------------+------+-----------------+-----------------+---------+-------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+-----------------+-----------------+---------+-------+------+----------+-------------+
| 1 | SIMPLE | t | NULL | ref | idx_title_title | idx_title_title | 2402 | const | 28 | 10.00 | Using where |
+----+-------------+-------+------------+------+-----------------+-----------------+---------+-------+------+----------+-------------+
> EXPLAIN SELECT g.genre FROM title_genre g JOIN title t ON g.title_id = t.title_id WHERE t.title = 'Interstellar' AND t.type = 'movie';
+----+-------------+-------+------------+------+-------------------------+--------------------+---------+-----------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+-------------------------+--------------------+---------+-----------------+------+----------+-------------+
| 1 | SIMPLE | t | NULL | ref | PRIMARY,idx_title_title | idx_title_title | 2402 | const | 28 | 10.00 | Using where |
| 1 | SIMPLE | g | NULL | ref | idx_title_genre_pk | idx_title_genre_pk | 4 | imdb.t.title_id | 1 | 100.00 | Using index |
+----+-------------+-------+------------+------+-------------------------+--------------------+---------+-----------------+------+----------+-------------+
> EXPLAIN SELECT t.title, r.average_rating, r.num_votes FROM title t JOIN title_rating r ON t.title_id = r.title_id WHERE t.title = 'Interstellar' AND t.type = 'movie';
+----+-------------+-------+------------+--------+-------------------------+-----------------+---------+-----------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+--------+-------------------------+-----------------+---------+-----------------+------+----------+-------------+
| 1 | SIMPLE | t | NULL | ref | PRIMARY,idx_title_title | idx_title_title | 2402 | const | 28 | 10.00 | Using where |
| 1 | SIMPLE | r | NULL | eq_ref | PRIMARY | PRIMARY | 4 | imdb.t.title_id | 1 | 100.00 | NULL |
+----+-------------+-------+------------+--------+-------------------------+-----------------+---------+-----------------+------+----------+-------------+
> EXPLAIN SELECT n.name AS name, tnc.character_name FROM name n JOIN title_name_character tnc ON n.name_id = tnc.name_id JOIN title t ON t.title_id = tnc.title_id WHERE t.title = 'Interstellar' AND t.type = 'movie';
+----+-------------+-------+------------+--------+--------------------------------------------------------------------+-----------------------------------+---------+------------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+--------+--------------------------------------------------------------------+-----------------------------------+---------+------------------+------+----------+-------------+
| 1 | SIMPLE | t | NULL | ref | PRIMARY,idx_title_title | idx_title_title | 2402 | const | 28 | 10.00 | Using where |
| 1 | SIMPLE | tnc | NULL | ref | idx_title_name_character_title_id,idx_title_name_character_name_id | idx_title_name_character_title_id | 4 | imdb.t.title_id | 4 | 100.00 | NULL |
| 1 | SIMPLE | n | NULL | eq_ref | PRIMARY | PRIMARY | 4 | imdb.tnc.name_id | 1 | 100.00 | NULL |
+----+-------------+-------+------------+--------+--------------------------------------------------------------------+-----------------------------------+---------+------------------+------+----------+-------------+
> EXPLAIN SELECT n.name, tp.category FROM title_principal tp JOIN title t ON t.title_id = tp.title_id JOIN name n ON n.name_id = tp.name_id WHERE t.title = 'Interstellar' AND t.type = 'movie';
+----+-------------+-------+------------+--------+-------------------------------------+-----------------+---------+-----------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+--------+-------------------------------------+-----------------+---------+-----------------+------+----------+-------------+
| 1 | SIMPLE | t | NULL | ref | PRIMARY,idx_title_title | idx_title_title | 2402 | const | 28 | 10.00 | Using where |
| 1 | SIMPLE | tp | NULL | ref | PRIMARY,idx_title_principal_name_id | PRIMARY | 4 | imdb.t.title_id | 7 | 100.00 | NULL |
| 1 | SIMPLE | n | NULL | eq_ref | PRIMARY | PRIMARY | 4 | imdb.tp.name_id | 1 | 100.00 | NULL |
+----+-------------+-------+------------+--------+-------------------------------------+-----------------+---------+-----------------+------+----------+-------------+
Calculating the Weighted Geometric Mean (552%)
- If you have specific priorities (e.g., latency is twice as important as throughput), you can use a weighted geometric mean.
Weighted Geometric Mean = (Throughput^weight_throughput * RPS^weight_latency)^(1 / (weight_throughput + weight_latency))- Pros: Allows for customization based on priorities.
- Cons: Requires assigning weights, which can be subjective.
Data Calculations (Assuming equal weights)
Input Data:
- Database: Throughput (TPS): 5200 Latency: 12 ms
- Cache: Throughput (TPS): 17200 Latency: 0.93 ms
Calculations:
- Database RPS:
1000 / 12 ms = 83.33 RPS - Cache RPS:
1000 / 0.93 ms = 1075.27 RPS - Database Geometric Mean:
(5200 * 83.33)^(1/2) = 658.26 - Cache Geometric Mean:
(17200 * 1075.27)^(1/2) = 4292.17
Based on Geometric Mean: ((4292.17 - 658.26) / 658.26) * 100 = 552%
Next Steps
This is just the first benchmark test in a number of evaluations of determining where Readyset can be considered as an essential component for database performance in your application infrastructure.
- Adding background write load to IMDb read-only tests.
- Different query patterns including aggregrations in IMDb.
- Larger database instances with higher thread executions.
- Determining effective Readyset cache instances sizes.
- Benchmarking with write-heavy workloads using my NYC Taxi .


{kind=link}