Common benchmark approaches fall into two general categories, synthetic testing and realistic testing.
You have the most generic operations from a synthetic test, starting with the most simple example using a single table, a single column, and for a single DML operation. A more real world example of synthetic testing provides a simple use-case of a common pattern such as the TPC-C Benchmark.
The problem with artificial benchmarking is their objective is to demonstrate the best performance for a given product and situation. I believe there is an absence of more realistic benchmarks that try to represent a production-like workload with production readable data and is easily extensible.
Available Benchmark Products
There are many different data benchmarking products. Some are generic benchmark products and some are designed to satisfy a specific usage pattern.
- sysbench Works with MySQL and PostgreSQL RDBMS as well as core CPU/Disk/Memory tests.
- pgbench for PostgreSQL benchmarks
- HammerDB RDBMS benchmarking
- ClickBench for Analytical workloads.
- YCSB Yahoo! Cloud Serving Benchmark for key/value workloads.
- NoSQLBench , for NoSQL workloads. e.g. Aiven .
- TLP Stress for Cassandra workloads.
- BMK-Kit for MySQL benchmarks.
Some products also tweak benchmarks to maximize the benefits/features/flags of their product, for example Yugabyte .
Sysbench Generic Test
Sysbench is one benchmarking product that supports RDBMS tests for MySQL and PostgreSQL as well as core CPU/Disk/Memory tests. It offers by default a number of generic read and read/write tests, with most simple testing using a single table structure with few columns.
mysql> show create table sbtest1\G
*************************** 1. row ***************************
Table: sbtest1
Create Table: CREATE TABLE `sbtest1` (
`id` int NOT NULL AUTO_INCREMENT,
`k` int NOT NULL DEFAULT '0',
`c` char(120) NOT NULL DEFAULT '',
`pad` char(60) NOT NULL DEFAULT '',
PRIMARY KEY (`id`),
KEY `k_1` (`k`)
) ENGINE=InnoDB;
mysql> select * from sbtest1 limit 1\G
*************************** 1. row ***************************
id: 1
k: 12467
c: 31451373586-15688153734-79729593694-96509299839-83724898275-86711833539-78981337422-35049690573-51724173961-87474696253
pad: 98996621624-36689827414-04092488557-09587706818-65008859162
TPC-C Benchmark Test
The TPC-C is a benchmark designed to measure the performance and scalability of transaction processing systems by simulating a wholesale supplier workload with multiple concurrent transactions. Various products provide a TPC-C implementation for comparison. This is a MySQL sysbench implementation created by Percona .
mysql> show tables;
+----------------+
| Tables_in_tpcc |
+----------------+
| customer |
| district |
| history |
| item |
| new_order |
| order_line |
| orders |
| stock |
| warehouse |
+----------------+
mysql> show create table customer\G
*************************** 1. row ***************************
Table: customer
Create Table: CREATE TABLE `customer` (
`c_id` int NOT NULL,
`c_d_id` int NOT NULL,
`c_w_id` int NOT NULL,
`c_first` varchar(16) CHARACTER SET latin1 COLLATE latin1_bin DEFAULT NULL,
`c_middle` char(2) CHARACTER SET latin1 COLLATE latin1_bin DEFAULT NULL,
`c_last` varchar(16) CHARACTER SET latin1 COLLATE latin1_bin DEFAULT NULL,
`c_street_1` varchar(20) CHARACTER SET latin1 COLLATE latin1_bin DEFAULT NULL,
`c_street_2` varchar(20) CHARACTER SET latin1 COLLATE latin1_bin DEFAULT NULL,
`c_city` varchar(20) CHARACTER SET latin1 COLLATE latin1_bin DEFAULT NULL,
`c_state` char(2) CHARACTER SET latin1 COLLATE latin1_bin DEFAULT NULL,
`c_zip` char(9) CHARACTER SET latin1 COLLATE latin1_bin DEFAULT NULL,
`c_phone` char(16) CHARACTER SET latin1 COLLATE latin1_bin DEFAULT NULL,
`c_since` datetime DEFAULT NULL,
`c_credit` char(2) CHARACTER SET latin1 COLLATE latin1_bin DEFAULT NULL,
`c_credit_lim` decimal(12,2) DEFAULT NULL,
`c_discount` decimal(4,4) DEFAULT NULL,
`c_balance` decimal(12,2) DEFAULT NULL,
`c_ytd_payment` decimal(12,2) DEFAULT NULL,
`c_payment_cnt` int DEFAULT NULL,
`c_delivery_cnt` int DEFAULT NULL,
`c_data` varchar(500) CHARACTER SET latin1 COLLATE latin1_bin DEFAULT NULL,
PRIMARY KEY (`c_w_id`,`c_d_id`,`c_id`),
KEY `c_w_id` (`c_w_id`,`c_d_id`,`c_last`,`c_first`),
KEY `idx_customer` (`c_w_id`,`c_d_id`,`c_last`,`c_first`),
CONSTRAINT `fkey_customer_1` FOREIGN KEY (`c_w_id`, `c_d_id`) REFERENCES `district` (`d_w_id`, `d_id`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1
1 row in set (0.00 sec)
mysql> select * from customer limit 1\G
*************************** 1. row ***************************
c_id: 1
c_d_id: 1
c_w_id: 1
c_first: RF85KZhVi1
c_middle: OE
c_last: BARBARBAR
c_street_1: zgad8YBo8P0
c_street_2: aWeshLHXWOjIi1dThe76
c_city: CKAY9ljFPeFCyivgHln
c_state: x3
c_zip: 798111111
c_phone: 8278866529096220
c_since: 2024-02-14 00:52:56
c_credit: BC
c_credit_lim: 50000.00
c_discount: 0.2500
c_balance: 477337.00
c_ytd_payment: 10.00
c_payment_cnt: 1
c_delivery_cnt: 0
c_data: 1 1 1 3 1 4,485.002024-02-14 15:14:49k52Lje9WB Sv8X4wrd1 1 1 1 1 4,014.002024-02-14 15:10:14k52Lje9WB SeYJZGhv1 1 1 1 1 3,560.002024-02-14 15:10:08k52Lje9WB SeYJZGhv1 1 1 9 1 771.002024-02-14 15:09:35k52Lje9WB WlIvPYzFzZ1 1 1 1 1 4,059.002024-02-14 15:09:13k52Lje9WB SeYJZGhv1 1 1 1 1 3,680.002024-02-14 15:08:05k52Lje9WB SeYJZGhv1 1 1 1 1 3,453.002024-02-14 15:06:31k52Lje9WB SeYJZGhv1 1 1 1 1 2,256.002024-02-14 15:05:35k52Lje9WB SeYJZGhv1 1 1
1 row in set (0.01 sec)
The Objective of a New Benchmark
My goal is to create a benchmark that is less dependent on a single benchmarking product, uses more realistic open datasets, which is actual data you can read and use (e.g. IMDb , NYC Taxi , MusicBrainz , eBikes, Weather etc). I also want to be able to create various workloads including a high read workload with typical CRUD queries and a high write workload with analytics queries, or examples that are a blend.
While a benchmark typically does not represent a more realistic production workload, the following two benchmarks are the first in a series of representations of database access patterns that you would see for a more realistic use case.
In the first benchmark we show a typical product application where there is a heavy read ratio for a collection of SQL statements around a given primary object. In this benchmark we are using the IMDb data sets enhanced with additional queries to build more relational data. The benchmark provides SQL statements you would combine into two individual APIs.
- The first is to use one to retrieve the details of a given person, and include their professions, movie titles, and characters in those roles.
- The second API example is for movies which provide details around the movies, genre, principal participants of the movies including writers, producers and other related people.
There is a separate example for TV series and TV episodes. Also needed is a small write/update load of the primary tables, performing inserts and updates to resemble a more realistic real world situation.
The second benchmark is a more typical high-write application that generally produces write once data. Predominantly the read workloads show aggregation of various attributes of this data. In this example, we will be using the NYC taxis data sets. Further examples will also use different eBikes datasets. This benchmark will demonstrate the streaming inserts of incoming records and provide several queries that show dashboard level detail of the inserted information.
These benchmarks are not an accurate representation of a full production system. However, they are designed to be more realistic than a synthetic benchmark. There will be additional examples using various data sets and data access patterns in the future.
What do you Measure?
The initial goal was to create a framework that used realistic understandable data, was easily extendable, and multi-product capable. You can do this all now.
The second goal is to use the framework to be able to plot several key metrics for each benchmark which is an iteration over a set of thread sizes. The first plots show the transaction throughput and latency for a benchmark using a set of different thread sizes and different workloads.
IMDb Name
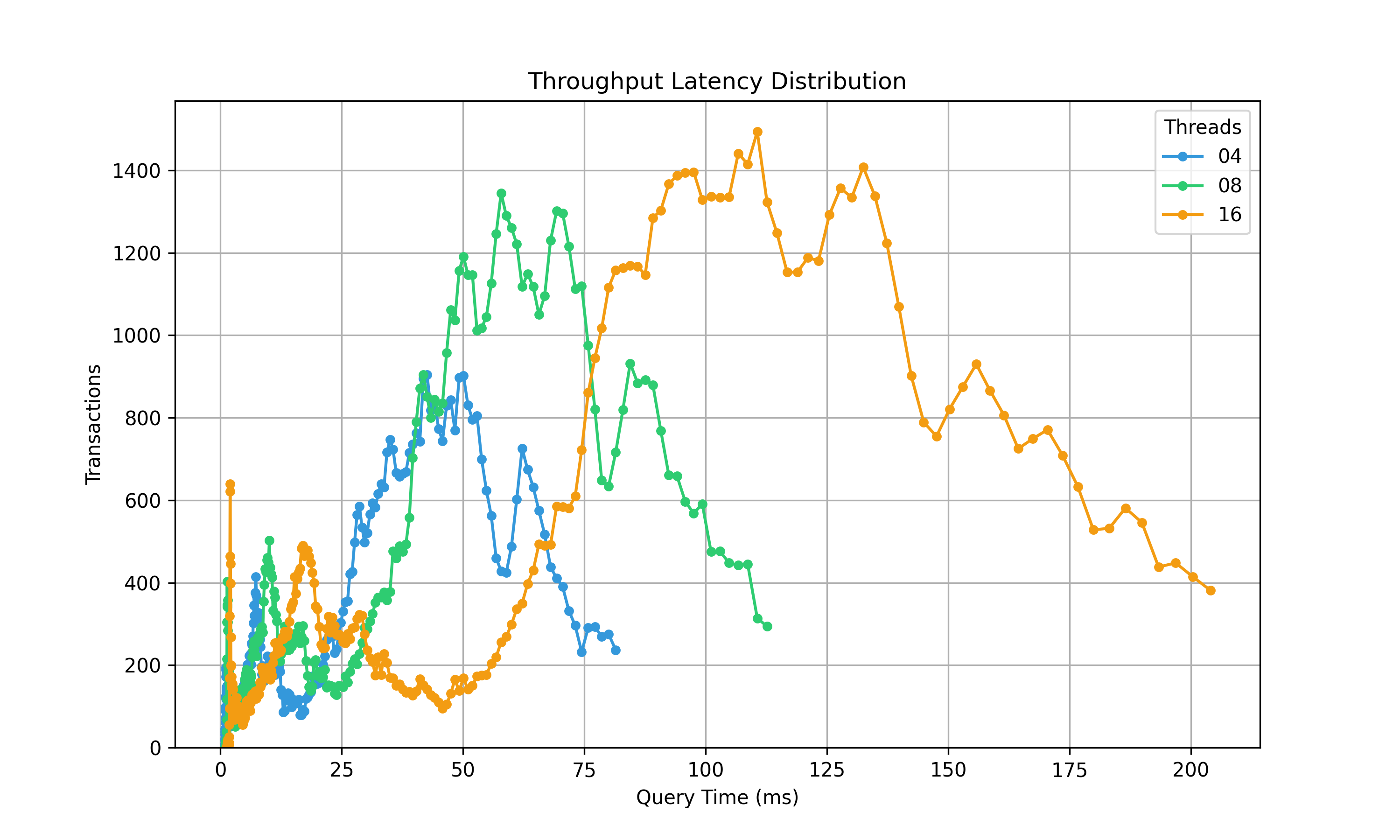
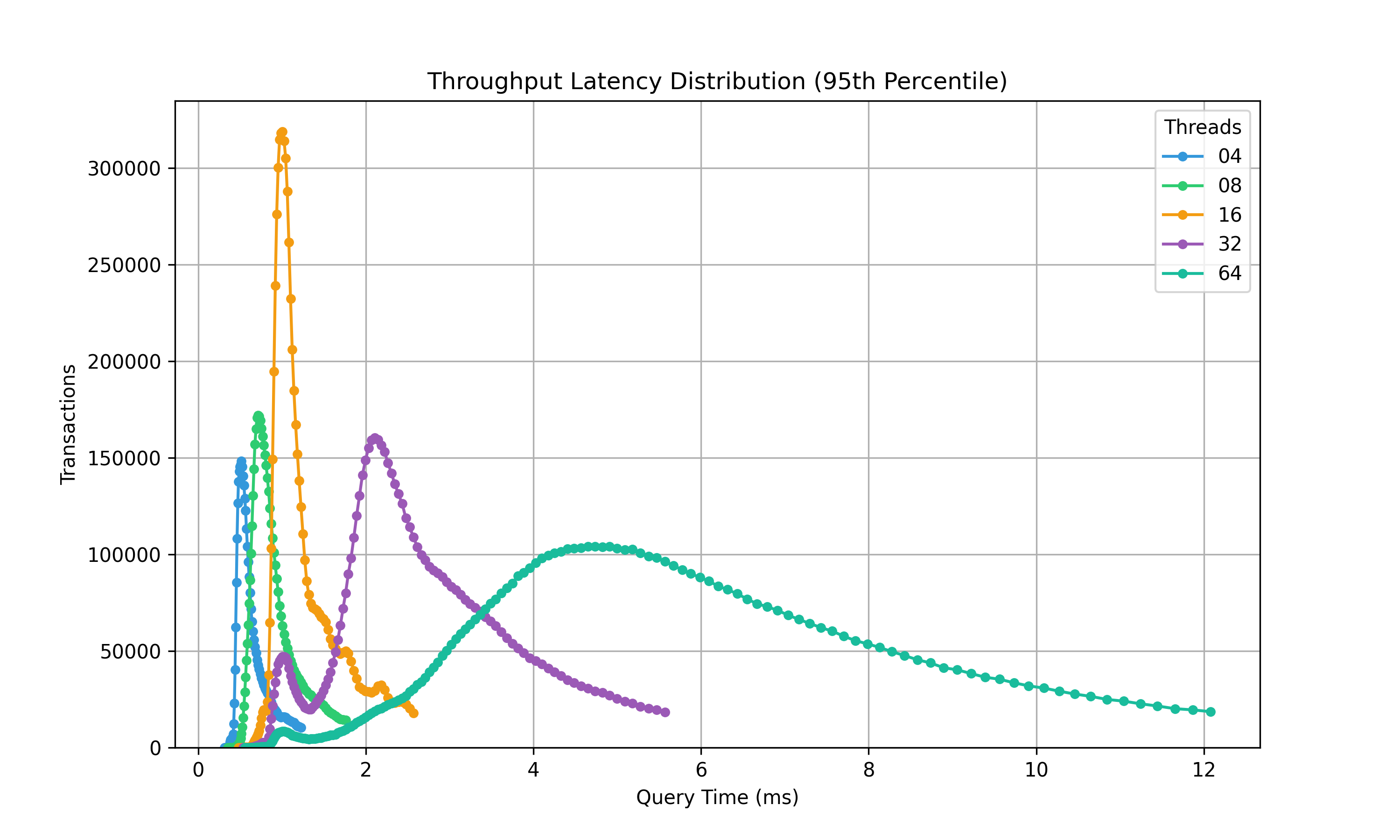
This is an example SQL transaction with 10 different SQL statement showing transaction distribution of latency for 4,8 and 16 SQL threads. The chart highlights that the range of execution time across the transaction is rather variable.
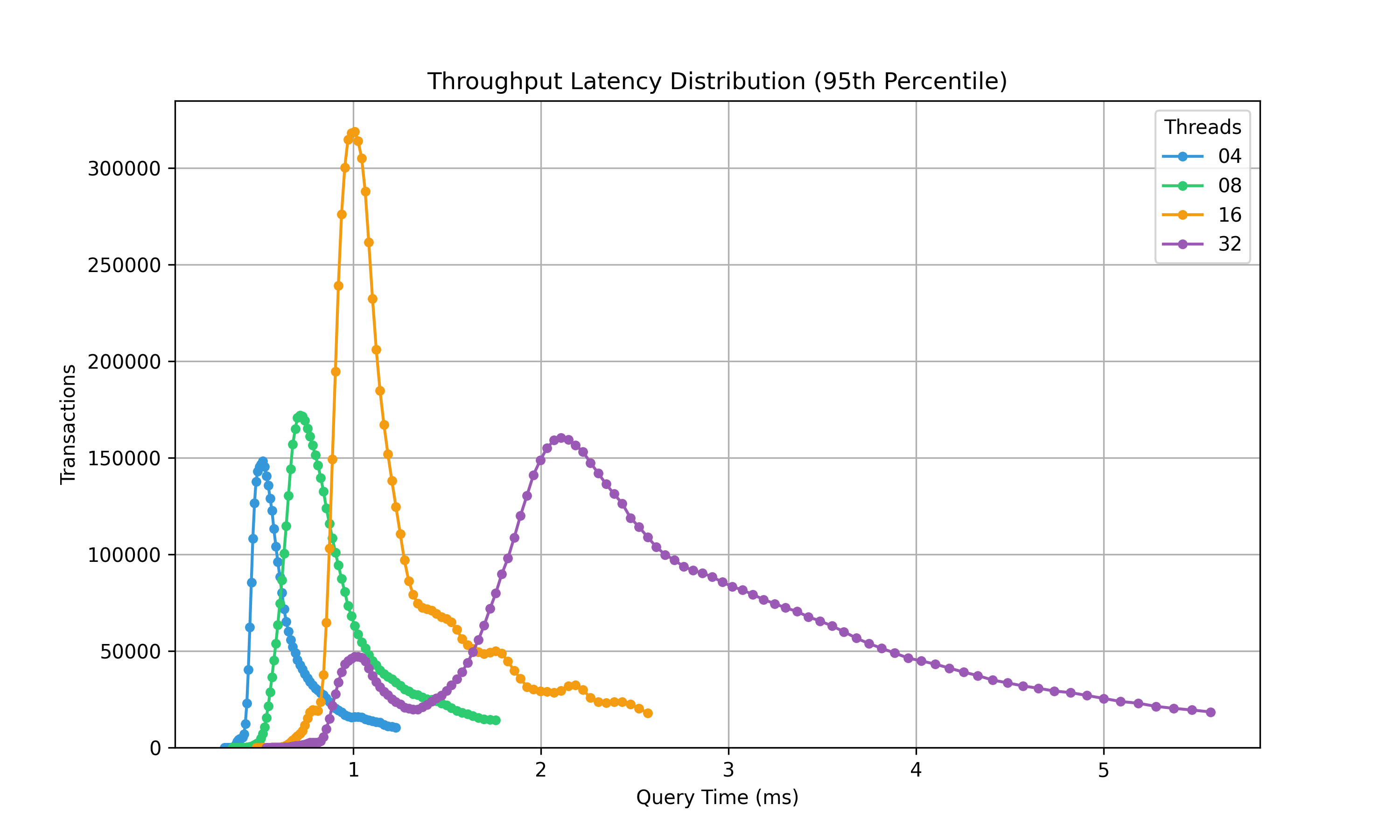
IMDb Title
This is an example SQL transaction with 3 different SQL statements and a much more common representation of distribution pattern. This is on an 8 core (16 threads) processor so you can see the distinct change after 16 threads, due to CPU starvation, causing SQL to take longer to execute, and not producing the throughput.
Comparing the same test on different equipment.
Here are some of the first examples running on local hardware for comparison purposese. I ran these on two different 8 core (16 threads) CPUs, an Intel i9 and an AMD Ryzen 7. In basic CPU throughput via CPUBenchmark the older Intel 9 is clocked as 14% closer.
The eyeball distribution for 16 SQL threads (matching 16 CPU threads) both show a peak around 1ms for 16 threads. It does show a higher volume of ~450k to ~330k between the two systems.
AMD Ryzen7
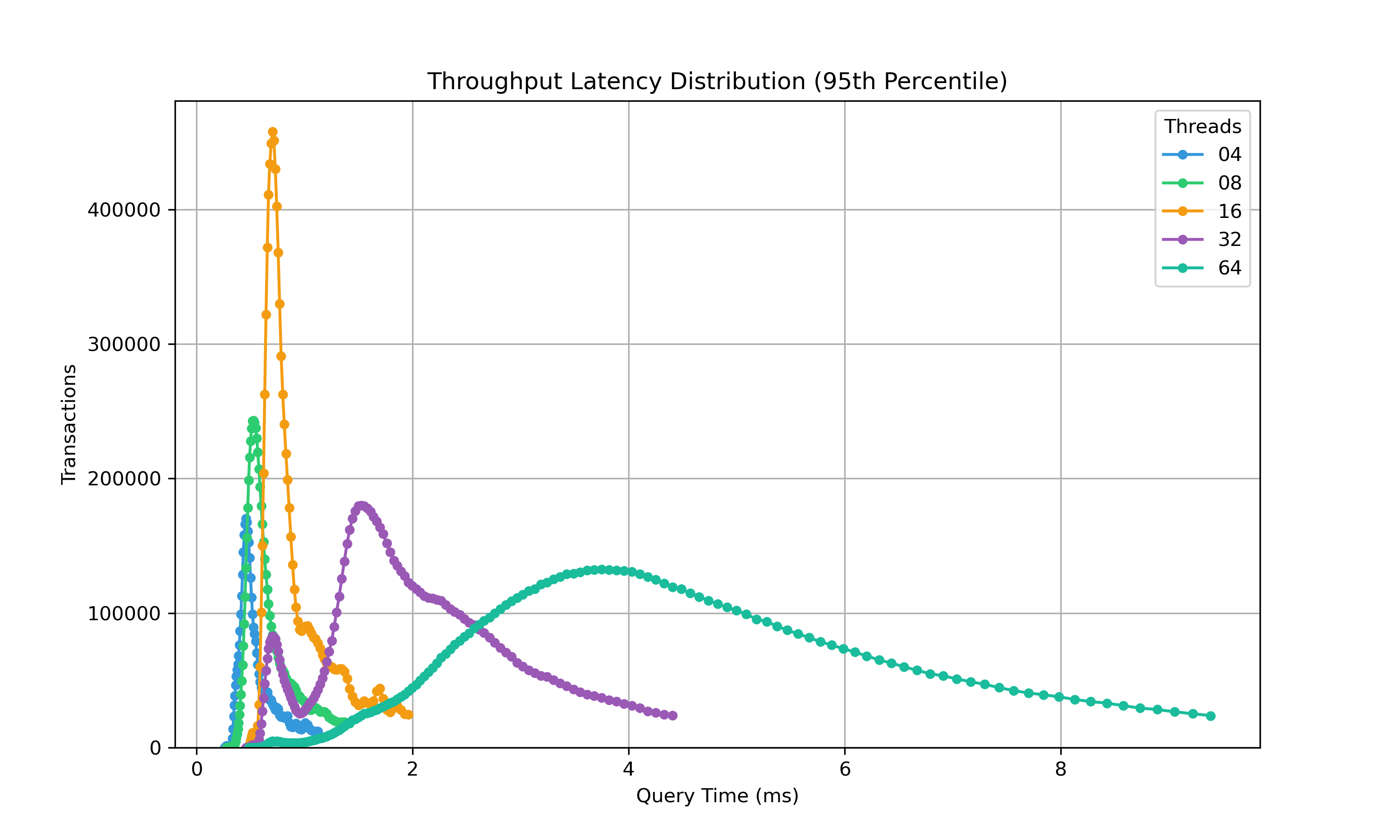
Intel i9
Whats Next
My next goal is to test these out on various sizes and configuration of AWS RDS to vett the first iteration of SQL, data and graphing. I also plan on plotting details of the actual query latency.


