AI-Assisted SQL Tuning
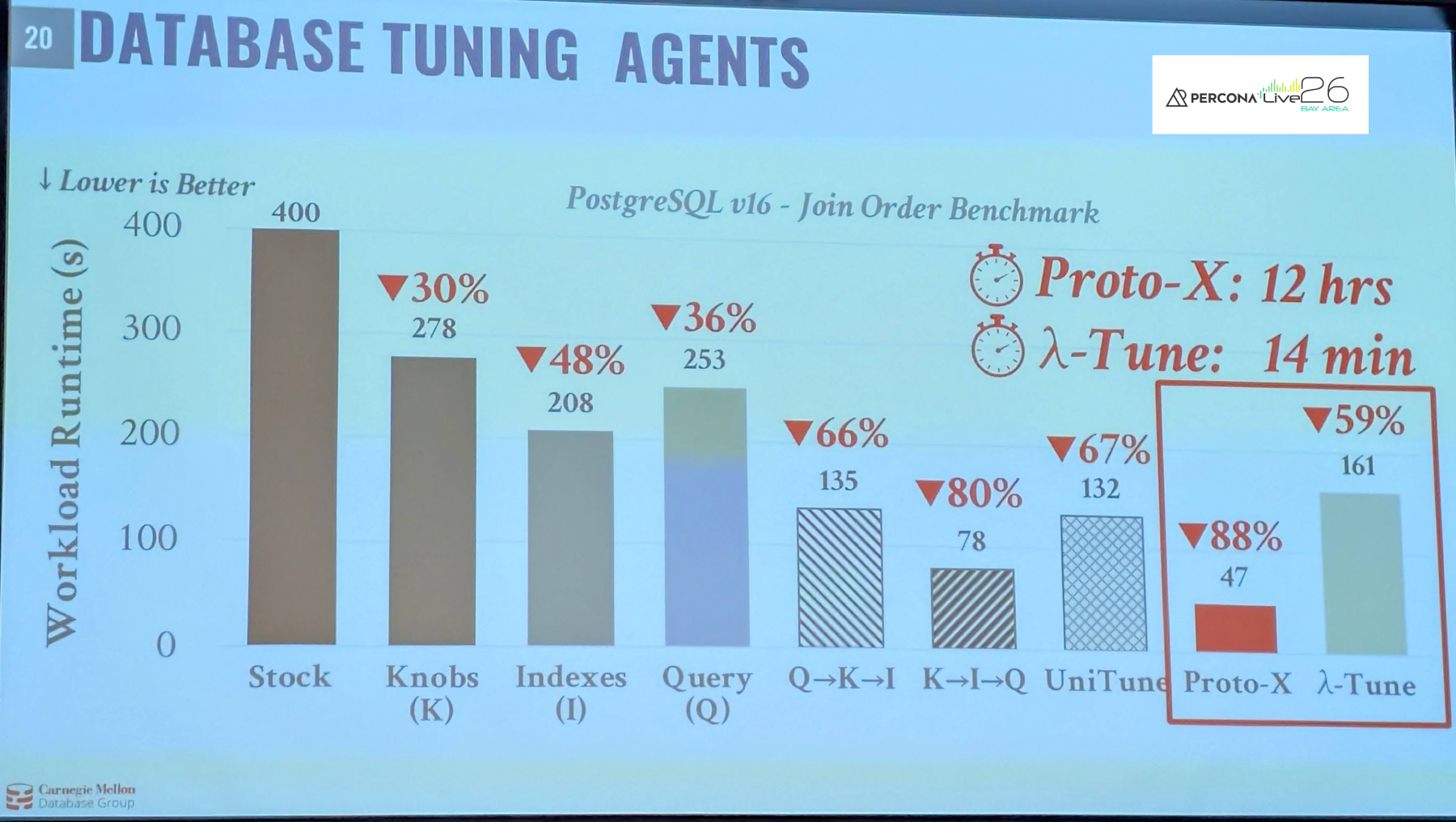
Last week in his keynote speech at Percona Live Bay Area 2026 , Andy Pavlo presented Databases: The Final Boss of Agents and provided some useful insights into query optimization of simulated workloads leveraging AI. In his example, he showed how using specific models to tune configuration, indexes, and queries at different stages and in a specific order overall made a significant improvement over an unconfigured setup. This alone would likely help many organizations with poorly optimized production workloads and serve as an automatic productivity tool of value. The UniTune, Proxo-X, and λ-Tune models were not as impactful for a stock benchmark overall, however they will likely prove more effective in production situations.
Andy pointed out during his talk that this work is academic and has not been validated on production workloads.
The Best Query Is No Query
In fact, the most effective way to tune a SQL query in a production workload is to simply eliminate it . In my professional consulting experience, this usually requires further explanation, but simply put: when looking at a single query, you are not evaluating the full landscape. When looking at all related SQL queries — those in a transaction, the query requests for a unit of work, or queries across the entire system — there are often a number of ways to reduce, simplify, combine, cache, or simply eliminate SQL statements. You perform this work before you look at configuration or structural improvements. I know I’ll have a job in performance engineering for a while yet, until AI works this out.
Covering Indexes in Practice
A further point in the presentation was that “index(a) is approximately equivalent to index(a,b)”. While in theory a concatenated index may not significantly improve the cardinality of an index, you first require statistics to validate that. In practice, different databases implement index structures very differently. Using MySQL as an example, the B+tree implementation of an InnoDB clustered primary key index and the B+tree implementation for secondary indexes operate differently.
Using a concatenated index(a,b) can have a profound impact on performance in MySQL. When this concatenated index is a covering index (i.e. all columns needed in a query are satisfied by the index alone) you can optimize query execution significantly. This is an artifact of the secondary index implementation, which does not store a pointer but instead stores the actual index values. As a sidebar, this is yet another reason why the architecture of well-defined column lengths and character sets becomes critical for large-scale performance improvements. I describe this in a real-life production implementation, Improving MySQL Performance with Better Indexes , where for a single statement of a 10-table join, adding a secondary column to existing indexes across a number of tables reduced query time from 175ms to 10ms. While that may not seem significant in absolute execution time, consider the 95% improvement of a query running billions of times a day (e.g. at 15,000 QPS). Often the best performance improvement is not to look at the slowest queries, but instead to look at the most frequently executed queries. For this consulting engagement I made no changes to configuration or code, and I added and removed no indexes — I simply improved existing indexes. I did not look at all SQL statements or slow SQL statements. I only needed to look at one key SQL statement and optimize it to realize massive infrastructure cost savings.
The Future
The promise of AI-assisted database tuning is real, and Andy’s work points to a future where much of the mechanical work of configuration and index tuning is automated. However, the gap between academic benchmarks and production workloads remains significant, and the most impactful optimizations still require understanding the full context of how and why SQL is executed in your system. Until AI can reason about business logic, application architecture, and the true cost of every query across an entire workload, experienced performance engineers will continue to find the improvements that automated tools miss. The best tool is still the one between your ears.